Resolved – ” Incompatible clusterIds in… ” in Multi Node Hadoop Cluster Setup
Currently, there are many startups / small companies and their customers, working on Data Analytics, ML, AI and related solutions. Due to their budget constraints, some of them don’t want to leverage Cloud-based storage. Alternatively, to process ingested data, they create basic Data Lake using HDFS.
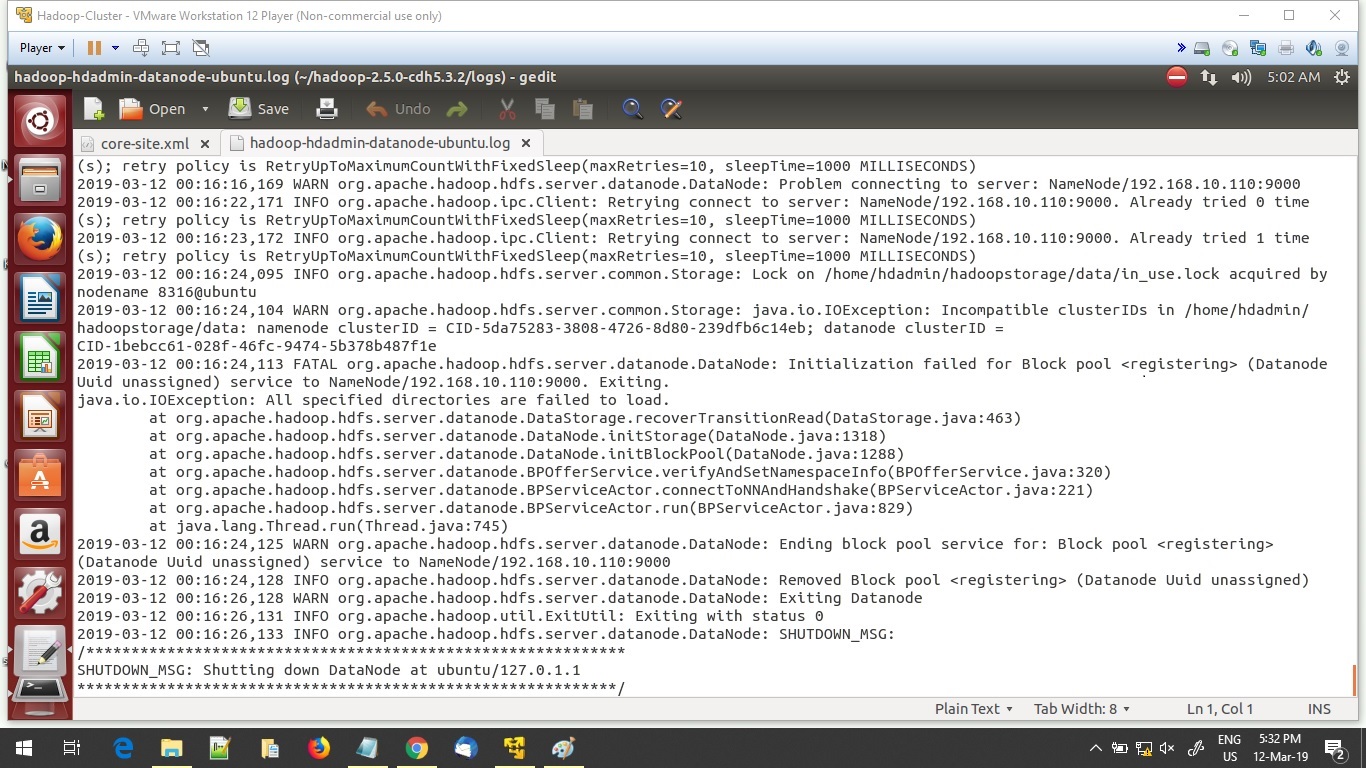
During this process, they might encounter the exception of “org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: Incompatible clusterIDs in /home/….”. while starting the Name Node or Master Node in a multi-node Hadoop Cluster.
This may occur in the following scenarios:
- After adding a new Data Node to the cluster
- If VERSION file already exists in the cluster for previous customer’s data storage operation
- Adding different operational node to the cluster, based on increasing data volume.
We have the following options to resolve this issue:
- If the cluster is running fine before creating new data node, and this issue pops up after creating the new data node, Delete VERSION file or delete entire “datanode” directories from the new Data Node if they exist.
The path of the directories can be found in hdfs-site.xml ../etc/hadoop
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dataNode</value>
</property>
- Copy the clusterID value from the VERSION file of NameNode and update in the Data Node VERSION file, if already available with a different value.
- If the data is not ingested in the cluster for processing, then format the Name node.
> hdfs namenode -format
Above command will completely format the meta-data related to all the data nodes (Fsimage files) in the NameNode. Ideally, we should not format the cluster if its is up and running and if data is already ingested into it.
Basically, contents in the directory specified for property name dfs.namenode.name.dir in hdfs-site.xml will be erased. Once, we start the cluster again then a new VERSION file will be generated with key clusterID and value as example CID-7adfse2d-fe9ed-snc6vt-fgcv4e-6dfsrcw and this has to be same across all the DataNode including Name Node to overcome incompatible clusterID id exception.
By Gautam Goswami
“If you are looking for setting up your own HDFS data lake for your organisation or your customer, we can collaborate with you and extend our support. Please reach out to us for details.”