Real-time Analytics with Apache DruidKislay Komal2024-04-30T18:16:34+00:00
is database built for data in motion
Sub-second queries at any scale
Execute OLAP queries on high-dimensional, high-cardinality data sets with billions to trillions of rows in milliseconds without pre-defining or caching queries.
Maximum concurrency at the cheapest cost
Build real-time analytics apps with constant performance that can handle 100–100,000 queries per second using a highly effective architecture that requires less infrastructure than other databases.
Real-time and historical insights
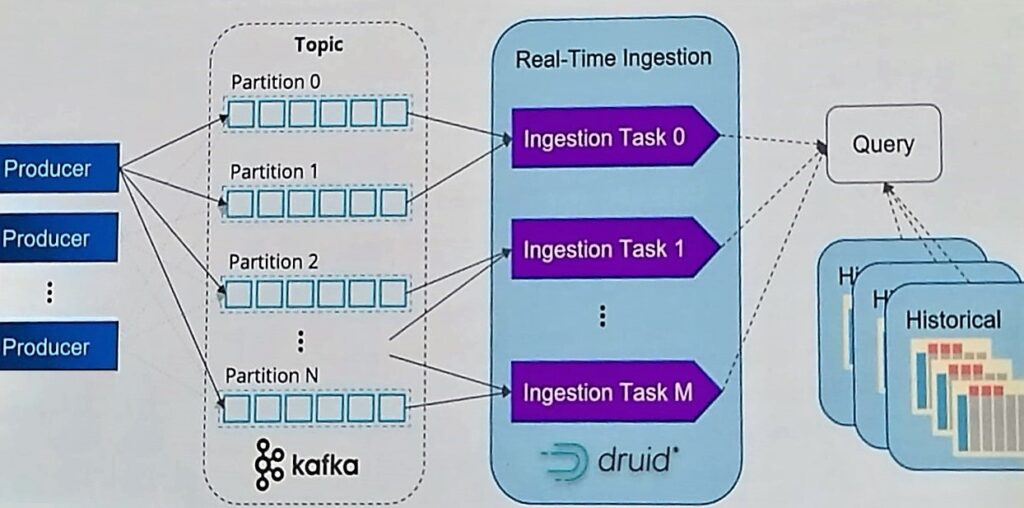
Druid’s native integration with Apache Kafka and Amazon Kinesis, which allows query-on-arrival at millions of events per second, low latency ingestion, and assured consistency, enables you to fully exploit the potential of streaming data.
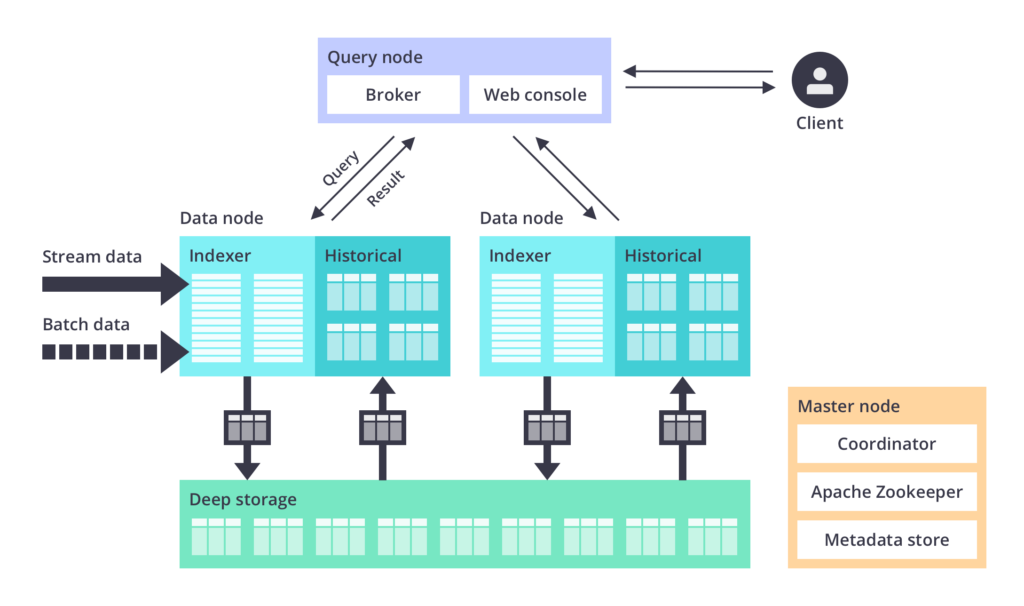
A high-performance, real-time analytics databaseDruid can process queries on streaming and batch data at scale and under heavy demand in less than a second.
Real time ingestion by Druid is as scalable as Kafka!
No connectors needed
Event triggered ingestion
Concurrency guaranteed
Analyzing in real time with Druid
Interactive Query Engine
Druid uses Scatter/Gather for high-speed queries, preloading data into RAM or local storage to avoid data movement and network latency
Tiering & QoS
Configurable tiering with Quality of Service enables optimal price-performance ratio for mixed workloads, guarantees priority and avoids resource conflicts
Optimized Data Format
Imported data is automatically columnarized, time-indexed, dictionary-encoded, bitmap-indexed, and type-compressed
Elastic Architecture
Loosely coupled ingestion, query, and orchestration components combined with a deep storage layer enable easy and fast scale-up and scale-out
True Stream Ingestion
A connector-free integration with streaming platforms enables query-on-arrival, high scalability, low latency, and guaranteed consistency
Non-stop Reliability
Automated data services including continuous backup, automatic recovery, and multi-node replication ensure high availability and durability
When do you need Druid?
Insertion rates are very high, but updates are less frequent.
Most of your queries are aggregation and reporting queries. For example, “group by” queries. You may also have search and scan queries.
You aim for query latencies of 100 ms to a few seconds.
Your data has a time component. Druid includes optimizations and design decisions specific to time.
You may have more than one table, but each query hits only one large distributed table. Queries can potentially access more than one smaller “lookup” table.
You have columns of data with high cardinality, e.g., URLs, user IDs, and you need fast counting and ranking across those columns.
You want to load data from Kafka, HDFS, flat files, or object stores such as Amazon S3
Setting up Druid to Work with Kafka
Success Stories
Real-time IoT Data Streaming & Analytics with Apache Kafka & Apache Druid
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.