Driving Business Growth with Apache Kafka – Flink – Druid
Driving Business Growth with Apache Kafka – Flink – DruidKislay Komal2024-04-19T16:46:09+00:00
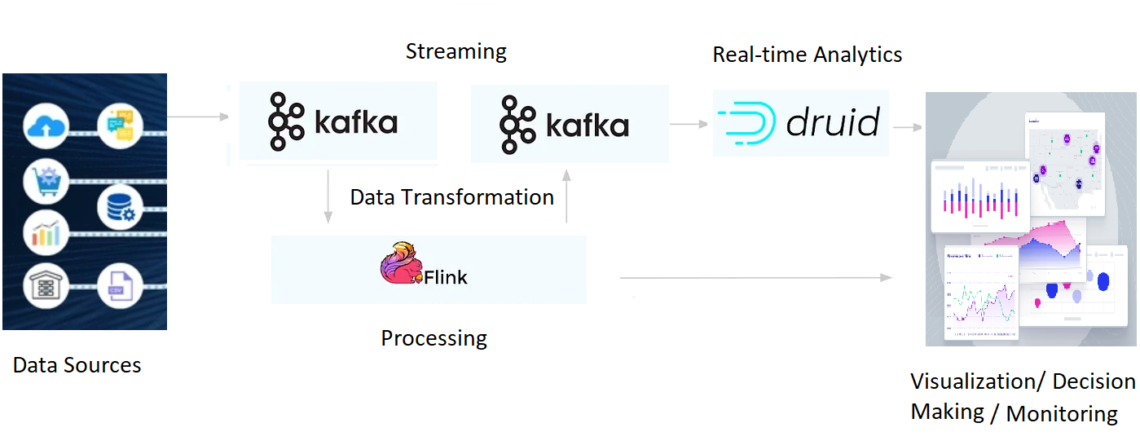
Irisidea builds real-time data streaming, processing and analytics applications using Apache Kafka-Flink-Druid
Why Kafka+Flink+Druid?
Organizations are increasingly looking for real-time performance from data teams.
Thus, the entire data workflow must be reconsidered. That explains why so many companies are embracing Kafka-Flink-Druid as the default free and open-source data architecture for building real-time data streaming, processing and analytics applications.
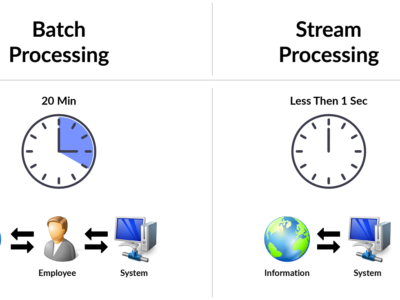
A batch workflow, calls for waiting at all stages and cant satisfy real-time data processing and analytics demands.
From data delivery and processing and to data analysis, the batch workflow needs waiting at every step, such as delivering data to ETL tools, bulk processing, importing data to the data warehouse, and querying the data. This makes it hard for teams, working with data employing batch workflows, to satisfy real-time data processing and analytics demands.
When used together, Apache Kafka, Flink, and Druid form a real-time data architecture
That removes all of those wait states. Combining all of these tools enables a diverse set of real-time applications.
Architecting real-time applications
Interactive Query Engine
Kafka-Flink-Druid builds a data architecture capable of delivering data youthfulness, magnitude and dependable performance throughout the data workflow, from the occurrence to data analysis to application.
Tiering & QoS
These are complementary stream-native technologies that can handle an extensive variety of real-time use cases.
Optimized Data Format
This architecture simplifies the development of real-time applications like visibility, customer-facing insights, security detection/diagnostics, IoT and telemetry analytics, and tailored suggestions.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.