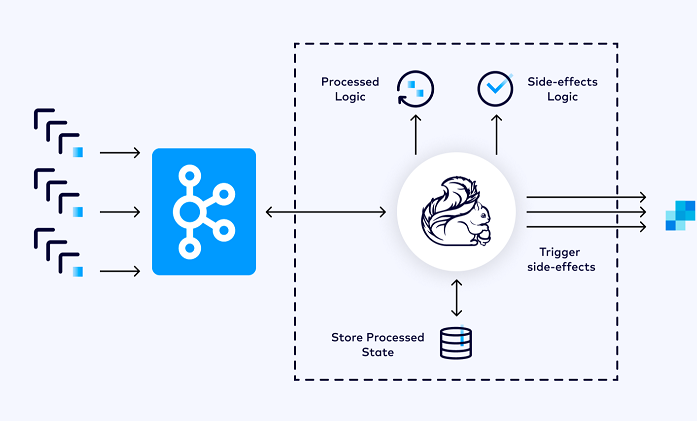
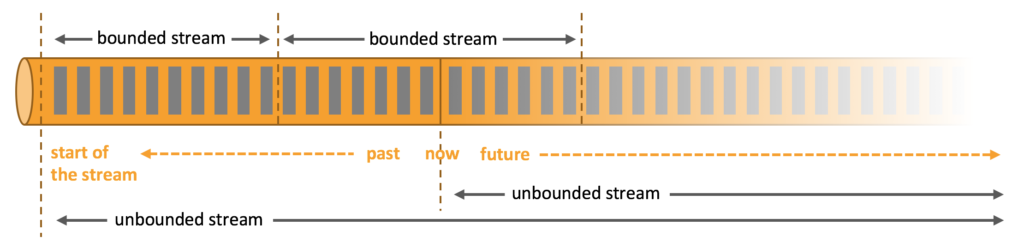
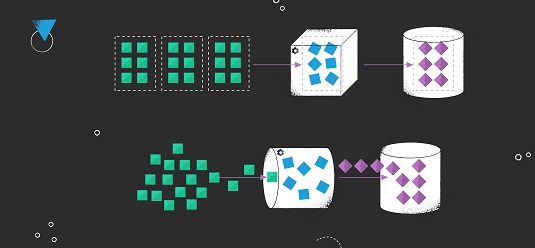
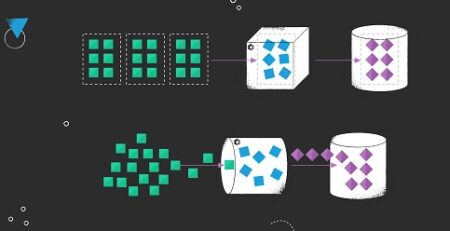
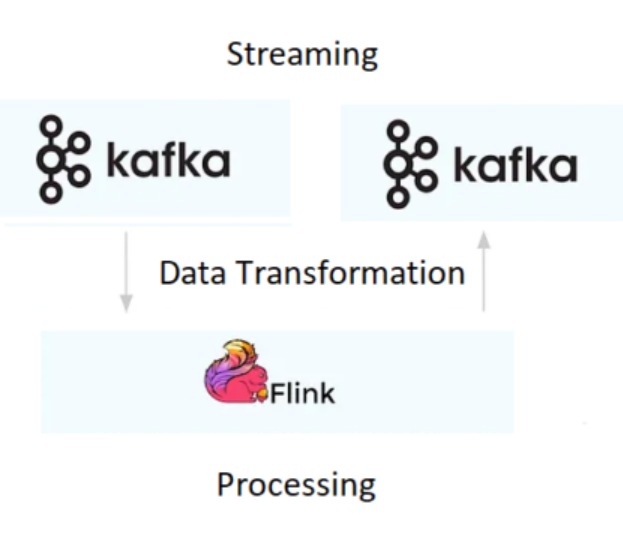
Unlike alternative systems such as ActiveMQ, RabbitMQ, etc., Kafka offers the capability to durably store data streams indefinitely, enabling consumers to read streams in parallel and replay them as necessary. This aligns with Flink’s distributed processing model and fulfills a crucial requirement for Flink’s fault tolerance mechanism.