04Jun
Driving Streaming Intelligence On-Premises: Real-Time ML with Apache Kafka and Flink
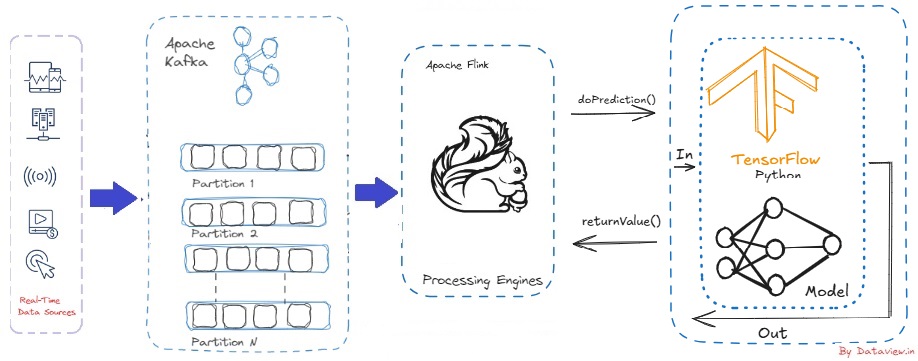
Lately, companies, in their efforts to engage in real-time decision-making by exploiting big data, have been inclined to find a suitable architecture for this data as quickly as possible. With many companies, including SaaS users, choosing to deploy their own infrastructures entirely on their own, the combination of Apache Flink and Kafka offers low-latency data pipelines that are built for complete reliability. Particularly due to the financial and technical constraints it brings, small and the medium size enterprises often have...