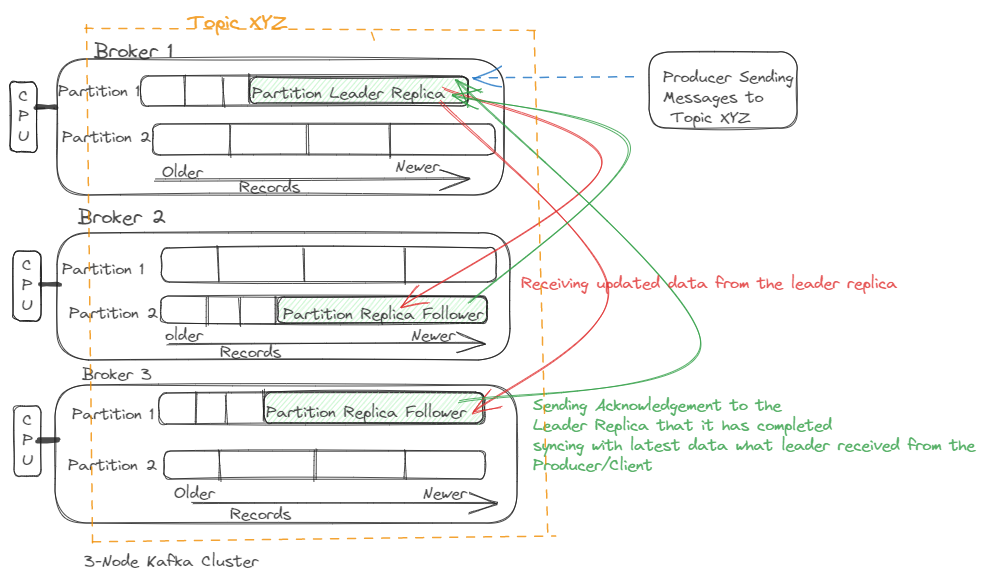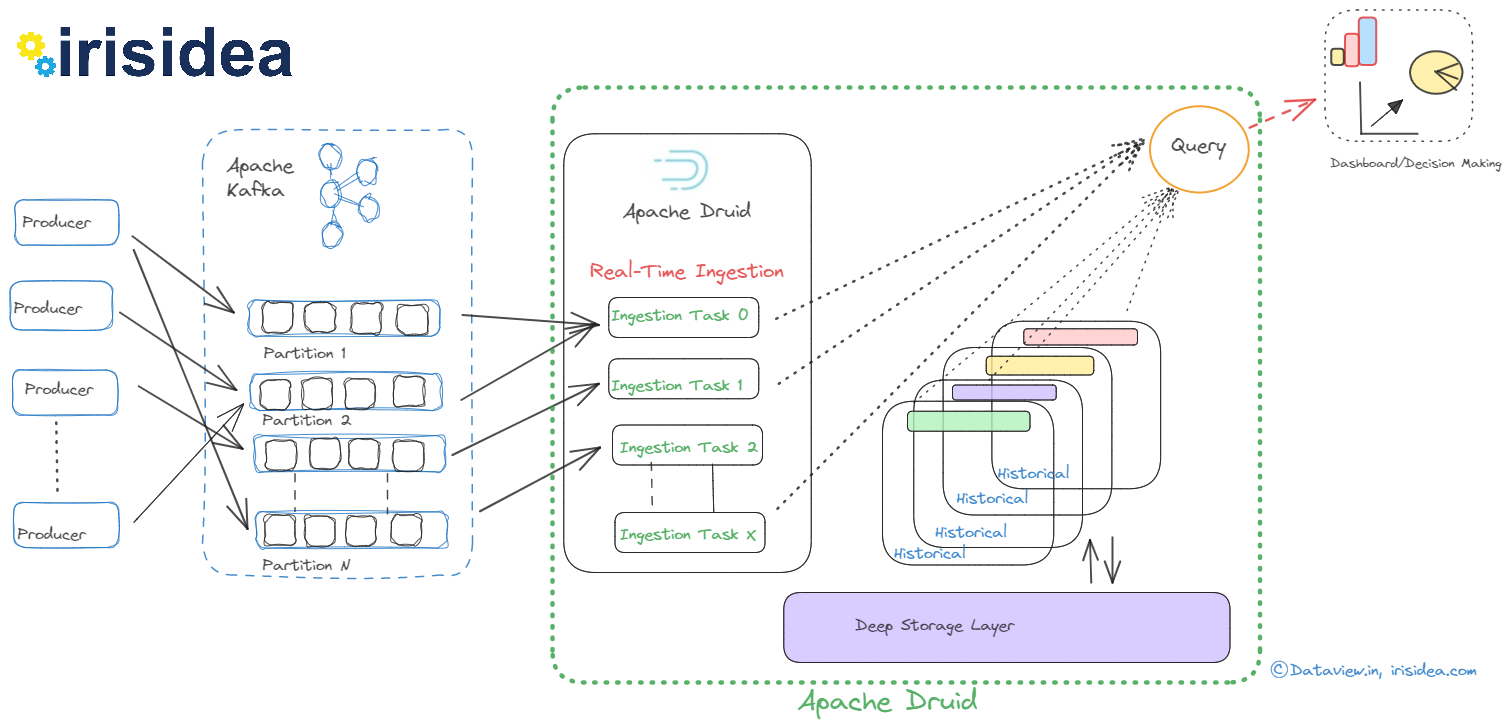
16Jun
Forging Apache Druid with Apache Kafka for real-time streaming analytics
A real-time analytics database called Apache Druid is developed for quick slice-and-dice analysis on massive data volumes. The best data for Apache Druid is event-oriented and frequently utilized as the database backend for analytical application GUIs and for highly concurrent APIs that require quick aggregations. Druid can be leveraged very effectively where real-time ingestion, fast query performance, and high uptime are crucial. At the other end, Apache Kafka is gaining outstanding momentum as a distributed event streaming platform with excellent...