24Feb
The Role of Materialized Views in Modern Data Stream Processing Architectures + RisingWave
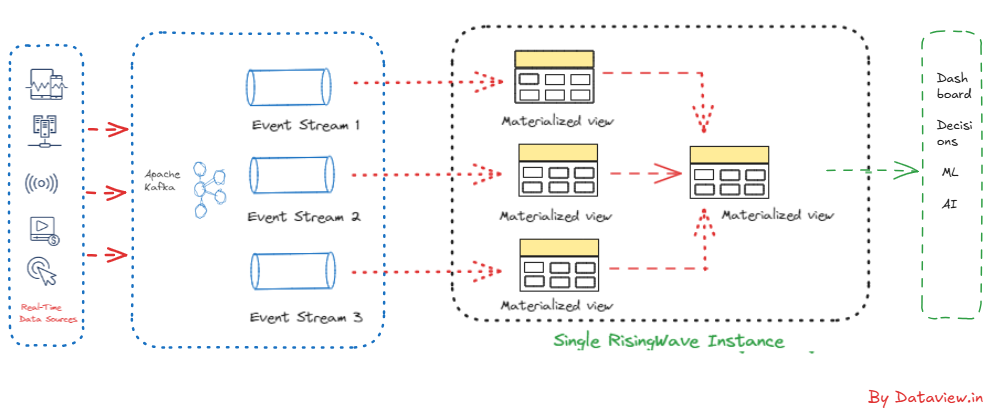
Incremental computation in data streaming means updating results as fresh data comes in, without redoing all calculations from the beginning. This method is essential for handling ever-changing information, like real-time sensor readings social media streams, or stock market figures. In a traditional, non-entrepreneurial calculation model, we need to process the entire dataset every time we get a new piece of data. It can be incompetent and slow. In incremental calculations, only the part of the result affected by new...