30Mar
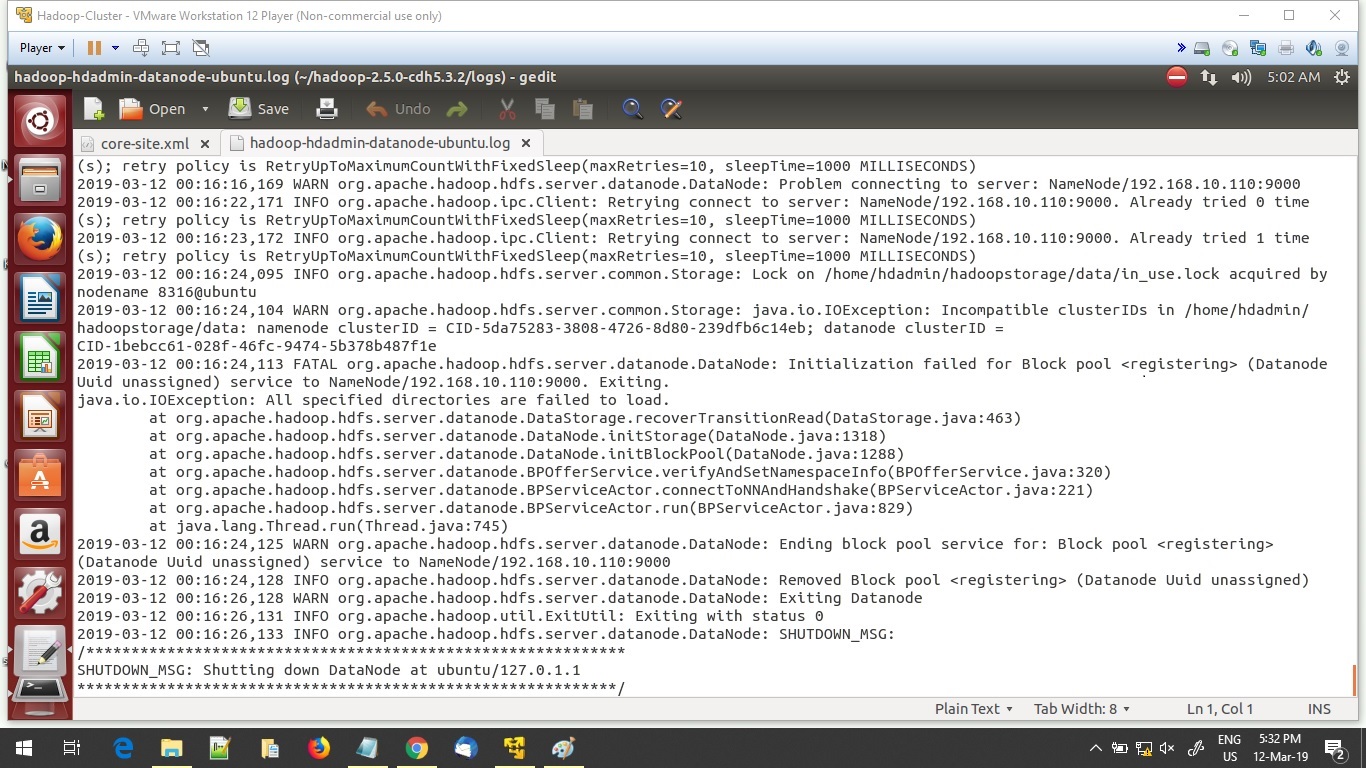
Error while batch processing of rest data persisted in Basic Hadoop based (HDFS) Data Lake “Permission denied: user=dr.who, access=READ_EXECUTE, inode=”/tmp”:hdadmin:supergroup:drwx……..”
Typically, persisting unstructured data and subsequent batch processing can be very costly and is not advisable for small organizations & startups, as cost is prime factor for them. A Hadoop based Data Lake using Map-Reduce, fits perfectly in this scenario which is not only cost effective but also scalable and easy to extend further. Though it may sound a great option to have, we might face issues while setting up the same and one of common issues is, error "Permission...