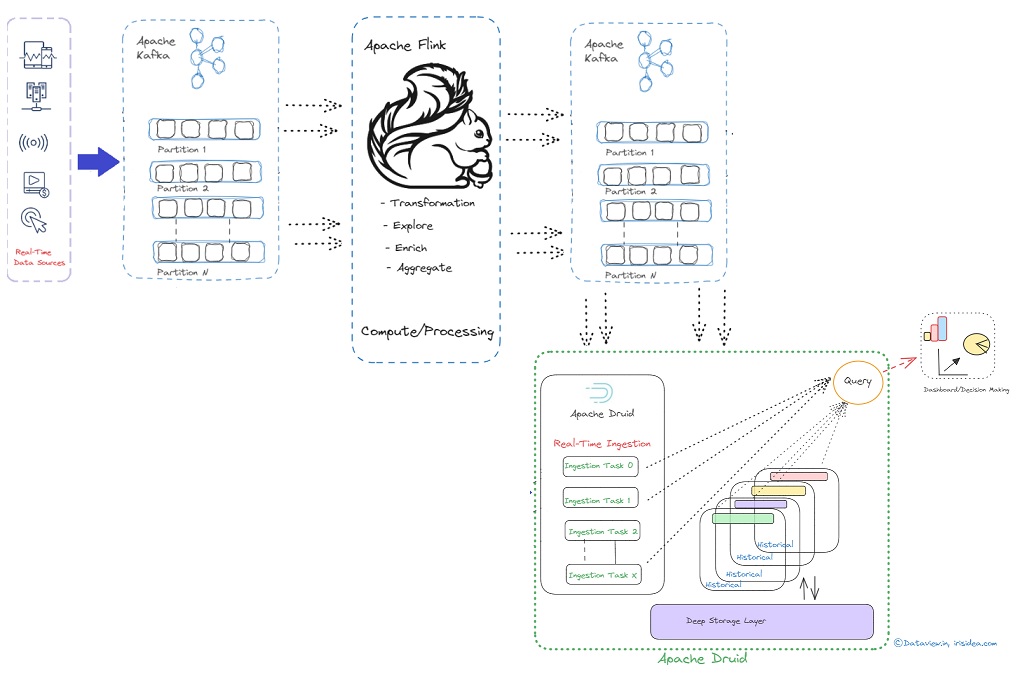
Transferring real-time data stream processed by Apache Flink to Kafka to Druid for analysis
Businesses can react quickly and effectively to user behavior patterns by using real-time analytics. This allows them to take advantage of opportunities that might otherwise pass them by and prevent problems from getting worse.
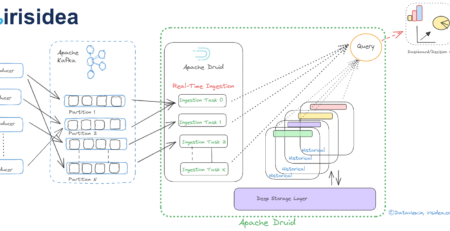
Apache Kafka, a popular event streaming platform, can be used for real-time ingestion of data/events generated from various sources across multiple verticals such as IoT, financial transactions, inventory, etc. This data can then be streamed into multiple downstream applications or engines for further processing and eventual analysis to support decision-making. Apache Flink serves as a powerful engine for refining or enhancing streaming data by modifying, enriching, or restructuring it upon arrival at the Kafka topic. In essence, Flink acts as a downstream application that continuously consumes data streams from Kafka topics for processing, and then ingests the processed data into various Kafka topics. Eventually, Apache Druid can be integrated to consume the processed streaming data from Kafka topics for analysis, querying, and making instantaneous business decisions.
In my previous write-up, I explained how to integrate Flink 1.18 with Kafka 3.7.0. Please click here to read. In this article, I will outline the steps to transfer processed data from Flink 1.18.1 to a Kafka 2.13-3.7.0 topic. A separate article detailing the ingestion of streaming data from Kafka topics into Apache Druid for analysis and querying was published a few months ago. You can read it here.
Execution Environment:-
- We configured a multi-node cluster (Three Node) where each node has a minimum of 8 GB RAM and 250 GB SSD along with Ubuntu-22.04.2 amd64 as the operating system.
- OpenJDK 11 is installed with JAVA_HOME environment variable configuration on each node.
- Python 3 or Python 2 along with Perl 5 is available on each node.
- Three node Apache Kafka-3.7.0 cluster has been up and running with Apache Zookeeper -3.5.6. on two nodes.
- Apache Druid 29.0.0 has been installed and configured on a node in the cluster where Zookeeper has not been installed for the Kafka broker. Zookeeper has been installed and configured on the other two nodes. The Leader broker is up and running on the node where Druid is running.
- Developed a simulator using the Datafaker library (https://www.datafaker.net/) to produce real-time fake financial transactional JSON records every 10 seconds of interval and publish them to the created Kafka topic
- Here is the sample data generated by the simulator
{“timestamp”:”2024-03-14T04:31:09Z “,”upiID”:”9972342663@ybl”,”name”:”Kiran Marar”,”note”:” “,”amount”:”14582.00″,”currency”:”INR”,”geoLocation”:”Latitude: 54.1841745 Longitude: 13.1060775″,”deviceOS”:”IOS”,”targetApp”:”PhonePe”,”merchantTransactionId”:”ebd03de9176201455419cce11bbfed157a”,”merchantUserId”:”65107454076524@ybl”} - Extract the archive flink-1.18.1-bin-scala_2.12.tgz on the node where Druid and the leader broker of Kafka is not running
Running a streaming job in Flink:–
We will dig into the process of extracting data from a Kafka topic where incoming messages are being published from the simulator, performing processing tasks on it, and then reintegrating the processed data back into a different topic of the multi-node Kafka cluster.
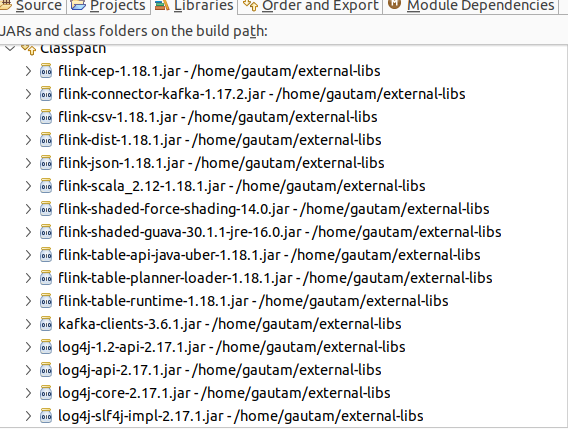
Developed a Java program (StreamingToFlinkJob.java) that was submitted as a job to Flink to perform the above-mentioned steps. Considering a window of 2 minutes and calculated the average amount transacted from the same mobile number (upi id) on the simulated UPI transactional data stream. The following list of jar files has been included on the project build or classpath.
- Using the below code, we can get the Flink execution environment inside the developed Java class
Configuration conf = new Configuration();
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);- Now we should read the messages/stream that has already been published by the simulator to the Kafka topic inside the Java program. Here is the code block
KafkaSource kafkaSource = KafkaSource.<UPITransaction>builder()
.setBootstrapServers(IKafkaConstants.KAFKA_BROKERS)// IP Address with port 9092 where leader broker is running in cluster
.setTopics(IKafkaConstants.INPUT_UPITransaction_TOPIC_NAME)
.setGroupId(“upigroup”)
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new KafkaUPISchema())
.build();- To retrieve information from Kafka, setting up a deserialization schema within Flink is crucial for processing events in JSON format, converting raw data into a structured form. Importantly, setParallelism needs to be set to no.of Kafka topic partitions else the watermark won’t work for the source, and data is not released to the sink.
DataStream<UPITransaction> stream = env.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofMinutes(2)), “Kafka Source”).setParallelism(1);With successful event retrieval from Kafka, we can enhance the streaming job by incorporating processing steps. The subsequent code snippet reads Kafka data, organizes it by mobile number (upiID), and computes the average price per mobile number. To accomplish this, we developed a custom window function for averaging and integrating watermarking to manage event time semantics adeptly. Here is the code snippet.
SerializableTimestampAssigner<UPITransaction> sz = new SerializableTimestampAssigner<UPITransaction>() {
@Override
public long extractTimestamp(Order order, long l) {
try {
SimpleDateFormat sdf = new SimpleDateFormat(“yyyy-MM-dd’T’HH:mm:ss’Z'”);
Date date = sdf.parse(order.eventTime);
return date.getTime();
} catch (ParseException e) {
return 0;
}}}; WatermarkStrategy<UPITransaction> watermarkStrategy = WatermarkStrategy.<UPITransaction>forBoundedOutOfOrderness(Duration.ofMillis(100)).withTimestampAssigner(sz);
DataStream<UPITransaction> watermarkDataStream = stream.assignTimestampsAndWatermarks(watermarkStrategy); //Instead of event time, we can use window based on processing time. Using TumblingProcessingTimeWindows
DataStream<TransactionAgg> groupedData = watermarkDataStream.keyBy(“upiId”).window(TumblingEventTimeWindows.of(Time.milliseconds(2500),
Time.milliseconds(500))).sum(“amount”);
.apply(new TransactionAgg()); Eventually, the processing logic (Computation of average price for the same UPI ID based on a mobile number for the window of 2 minutes on the continuous flow of transaction stream) is executed inside Flink.
//Window function to calculate the average amount on each upi ID or mobile number
public class TransactionAgg
implements WindowFunction<UPITransaction, TransactionAgg, Tuple, TimeWindow> {@Override
public void apply(Tuple key, TimeWindow window, Iterable<UPITransaction> values, Collector<TransactionAgg> out) {
Integer sum = 0; //Consider whole number
int count = 0;
String upiID = null ;
for (UPITransaction value : values) {
sum += value.amount;
upiID = value.upiID;
count++;
}TransactionAgg output = new TransactionAgg();
output.upiID = upiID;
output.eventTime = window.getEnd();
output.avgAmount = (sum / count);
out.collect( output);
}}
- We have processed the data, the next step is to serialize the object and send it to a different Kafka topic. Added a KafkaSink in the developed java code (StreamingToFlinkJob.java) to send the processed data from Flink engine to different Kafka topic created on multi-node Kafka cluster. Here is the code snippet to serialize the object before sending/publish to the Kafka topic
public class KafkaTrasactionSinkSchema implements KafkaRecordSerializationSchema<TransactionAgg> {@Override
public ProducerRecord<byte[], byte[]> serialize(
TransactionAgg aggTransaction, KafkaSinkContext context, Long timestamp) {
try {
return new ProducerRecord<>(
topic,
null, // not specified partition so setting null
aggTransaction.eventTime,
aggTransaction.upiID.getBytes(),
objectMapper.writeValueAsBytes(aggTransaction));
} catch (Exception e) {
throw new IllegalArgumentException(
“Exception on serialize record: ” + aggTransaction, e);
}}}- The below code block to sink the processed data sending it back to a different Kafka topic.
KafkaSink<TransactionAgg> sink = KafkaSink.<TransactionAgg>builder()
.setBootstrapServers(IKafkaConstants.KAFKA_BROKERS)
.setRecordSerializer(new KafkaTrasactionSinkSchema(IKafkaConstants.OUTPUT_UPITRANSACTION_TOPIC_NAME))
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
groupedData.sinkTo(sink); // DataStream that created above for TransactionAgg
env.execute();Connecting Druid with Kafka topic:-
In this final step, we need to integrate Druid with the Kafka topic to consume the processed data stream that is continuously published by Flink. With Apache Druid, we can directly connect Apache Kafka so that real-time data can be ingested continuously and subsequently queried to make business decisions on the spot without interventing any third-party system or application. Another beauty of Apache Druid is that we need not configure or install any third-party UI application to view the data that landed or is published to the Kafka topic. To condense this article, I omitted the steps for integrating Druid with Apache Kafka. However, a few months ago, I published an article on this topic. You can read it here and follow the same approach.
I hope you enjoyed reading this. If you found this article valuable, please consider liking and sharing it.
By