11Apr
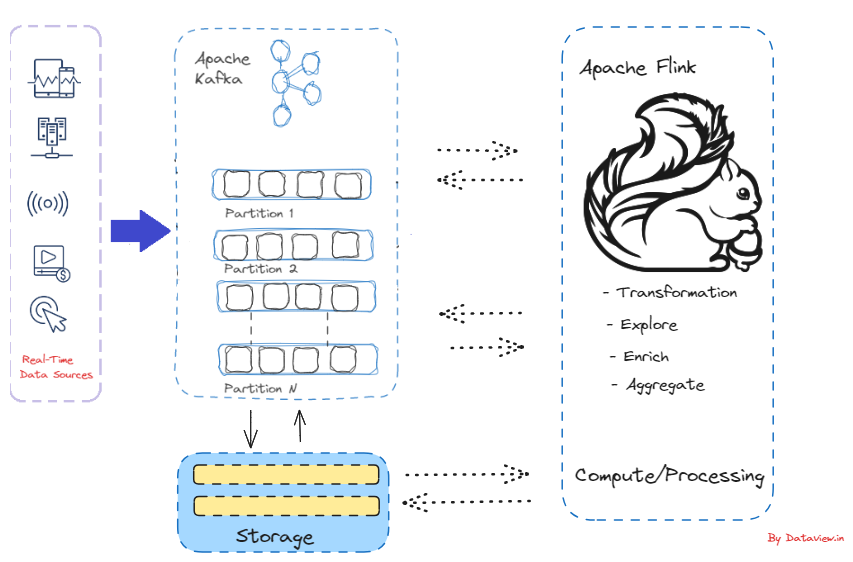
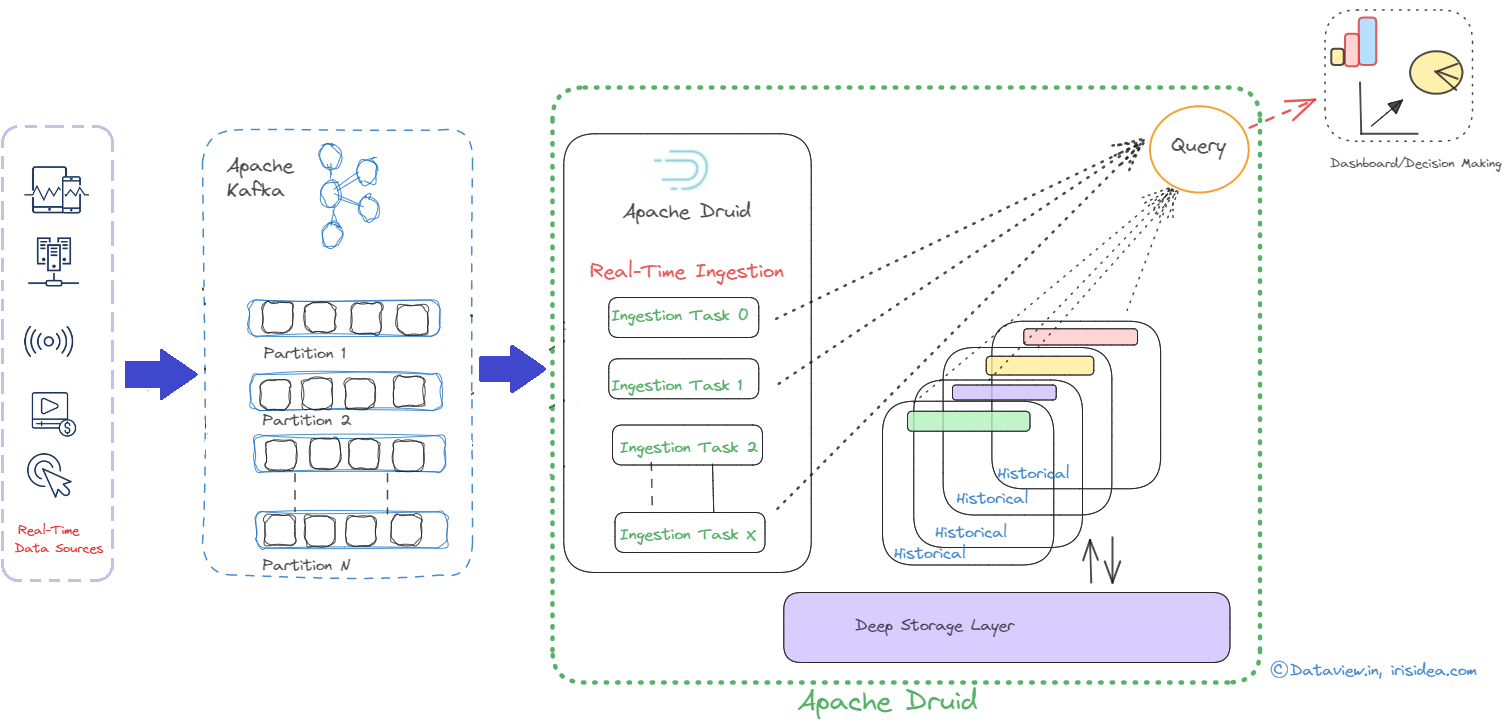
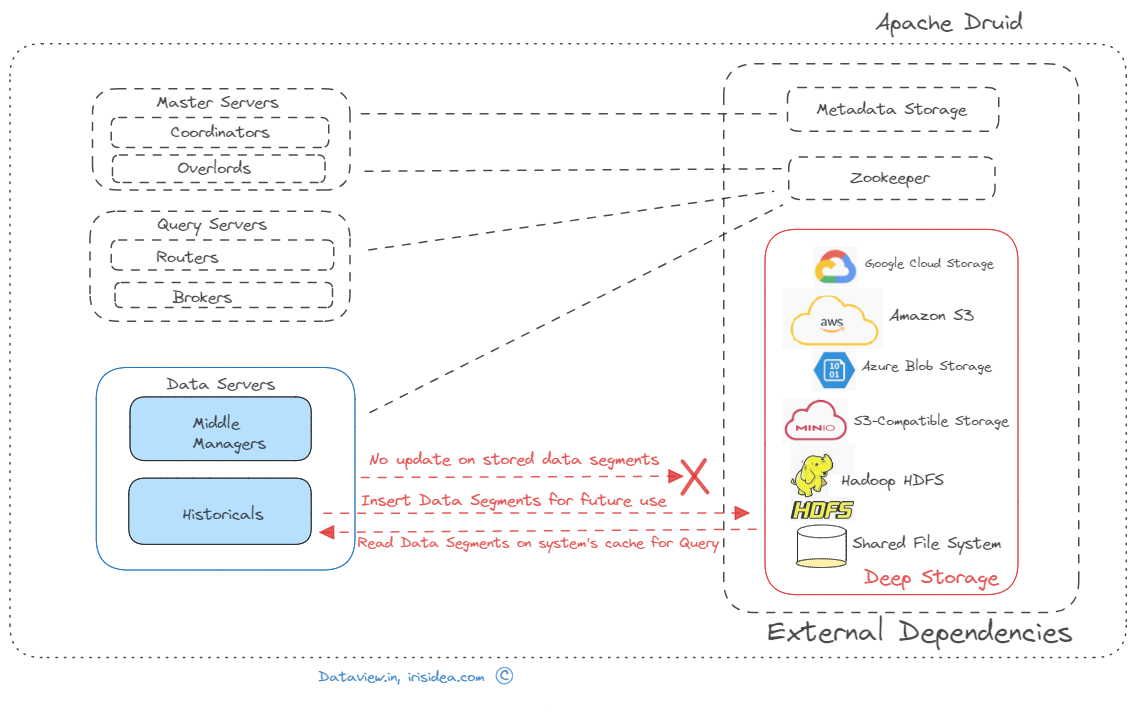
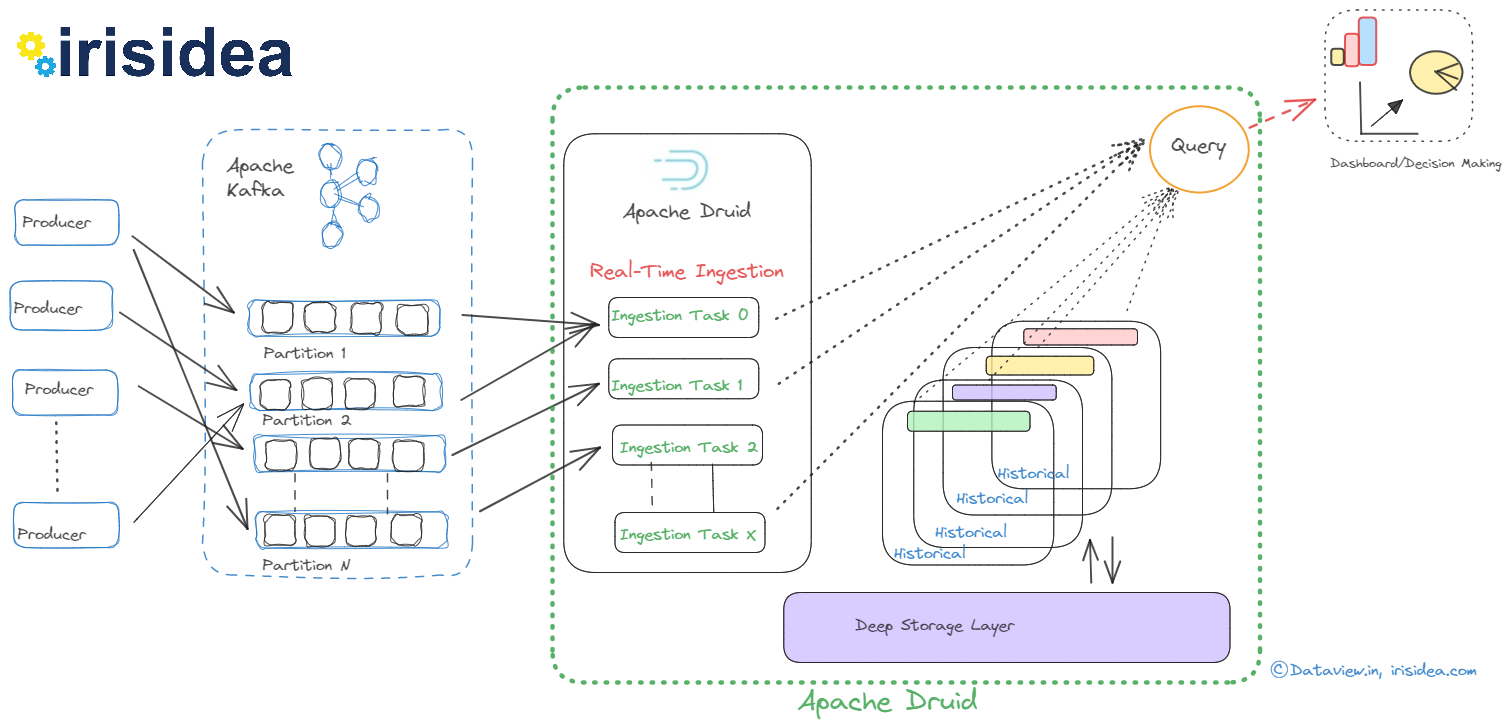
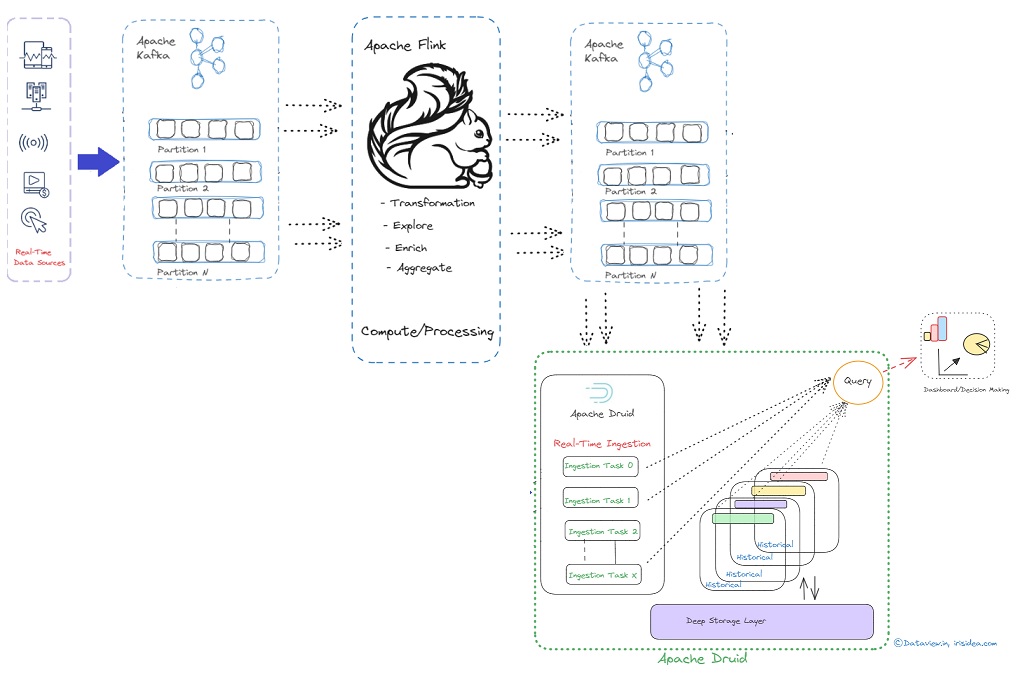
Transferring real-time data stream processed by Apache Flink to Kafka to Druid for analysis
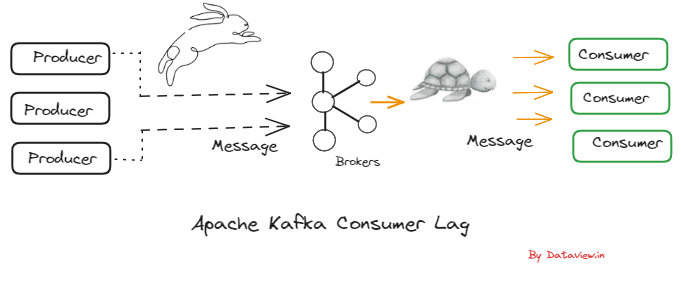
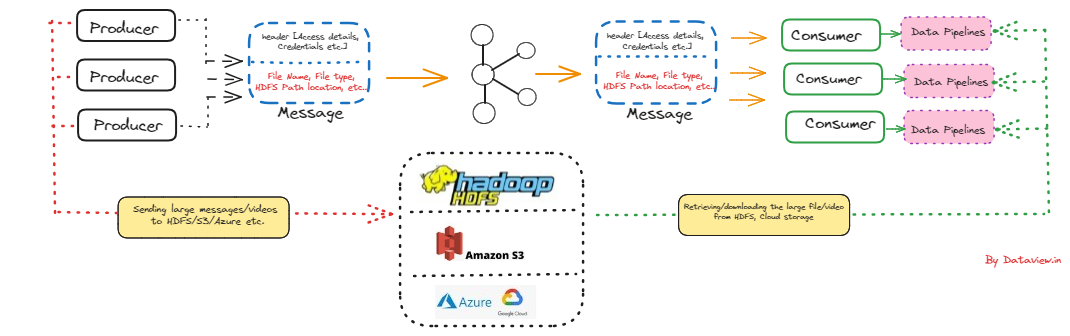
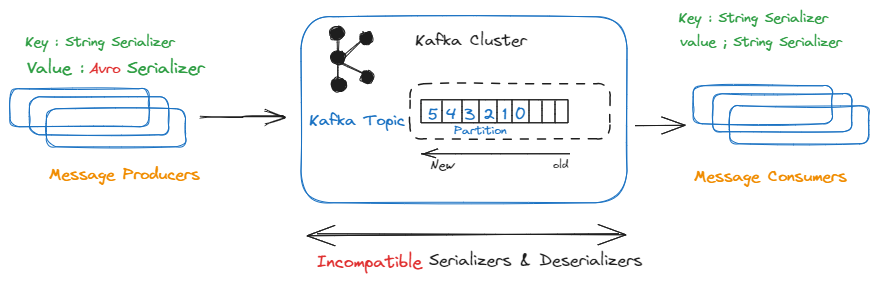
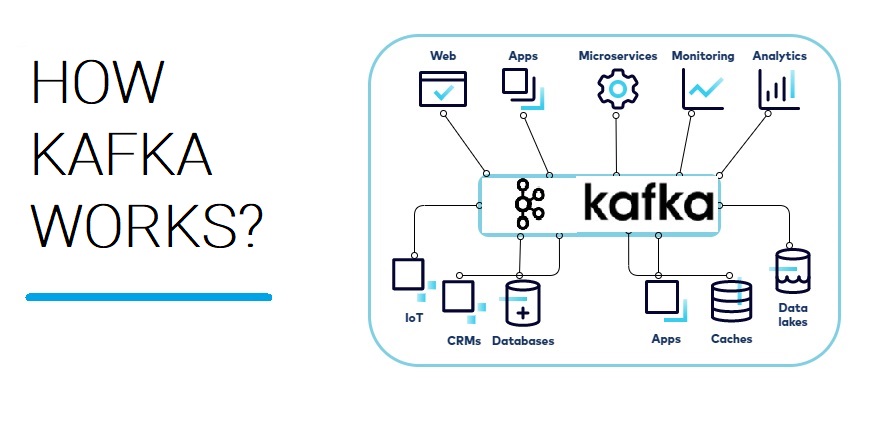
Businesses can react quickly and effectively to user behavior patterns by using real-time analytics. This allows them to take advantage of opportunities that might otherwise pass them by and prevent problems from getting worse. Apache Kafka, a popular event streaming platform, can be used for real-time ingestion of data/events generated from various sources across multiple verticals such as IoT, financial transactions, inventory, etc. This data can then be streamed into multiple downstream applications or engines for further processing and eventual...