Dark Data Demystified: The Role of Apache Iceberg
Lurking in the shadows of every organization is a silent giant—dark data. Undiscovered log files, unread emails, silent sensor readings, and decades-old documents collecting digital dust are all examples of the vast amount of data that companies unwittingly bury. Not only are these worthless artifacts, but they have the potential to be treasure troves that have been shut down because of antiquated systems, a lack of funding, or just plain negligence. Whether or not this data is structured, it contains opportunities, insights, and trends that could completely change a business’s approach. The turnabout? Most companies aren’t even aware that they have it. Unlocking dark data isn’t just a choice with the correct tools; it’s a race against the clock and other rivals to discover the hidden power before someone else does.
Dark data can take many different forms.
- Technical events are tracked by server and system log files, which are frequently left unused. Over time, old emails and attachments accumulate. Support centers keep track of customer chat logs and call recordings. For compliance or safety purposes, security cameras record video. Location data is produced by IoT sensors and mobile devices.
- To comply with regulations, businesses maintain financial records and transaction histories. Former employee data, such as project documents or old HR files, is inactive. Customer feedback or survey responses are left unanalyzed.
- When no one examines stored medical images, such as MRIs and X-rays, for insights, they can become dark data in the healthcare industry.
- Retail companies frequently don’t use browsing and purchase histories from their customers.
These examples illustrate how gray data exists as structured, semi-structured, and unstructured information in all industries. This presents both a challenge and an opportunity for businesses willing to explore it.
Apache Iceberg as the Engine to Explore Dark Data:

Apache Iceberg is a powerful open table format designed to handle large-scale analytics on massive datasets, making it an ideal solution for unlocking the hidden potential of dark data. Unlike traditional data storage systems that struggle with complexity and performance at scale, Iceberg enables seamless data management with support for schema evolution, ACID transactions, and time-travel queries. This means businesses can efficiently organize and query previously unused data such as old logs, sensor feeds, and archival records without compromising data integrity or performance. By using Iceberg, organizations can bring structure to chaos, enabling modern analytics engines like Apache Spark, Trino, or Flink to surface meaningful insights buried deep within dark data. In essence, Apache Iceberg acts as a bridge between forgotten data and actionable intelligence.
Processing dark data using Apache Iceberg:
Several crucial steps are involved in processing dark data with Apache Iceberg, all of which are intended to give unused data structure, accessibility, and analytical value.
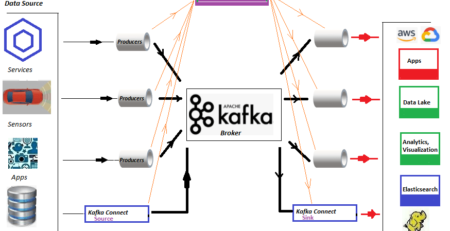
- Ingest dark data into a Data Lake using tools like Apache NiFi, AWS Glue, Apache Kafka, custom ETL jobs
- Clean and Transform as the dark data frequently appears in disorganized formats. Cleaning, normalizing and converting this data into structured formats (such as Parquet or ORC) using a data processing engine. We can leverage the tools like Apache Spark, Apache Flink
- After cleaning, load the transformed data into Apache Iceberg tables, which are optimized for analytical workloads and provide features like schema evolution, partitioning, and time travel.
- We can now query dark data using SQL engines after it has been organized and saved in Iceberg. This facilitates the discovery of patterns, irregularities, or insights from unexplored data.
The steps outlined above are high-level conceptual steps for processing dark data. In a real-time scenario, we would need to include more technical steps and procedures, involving various tools and frameworks, before reaching the dashboard to make business decisions based on the processed dark data.
I hope you enjoyed reading this. If you found this article valuable, please consider liking and sharing it.
– By Gautam Goswami