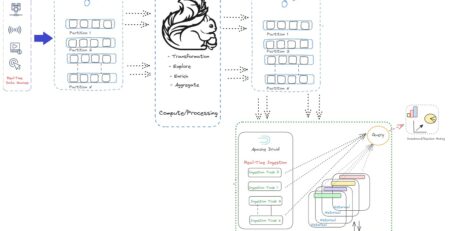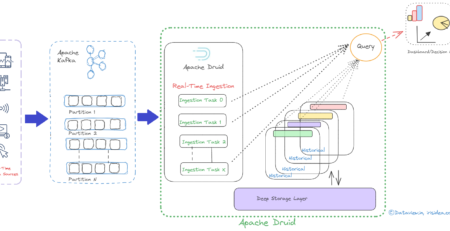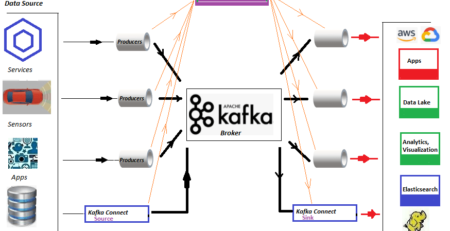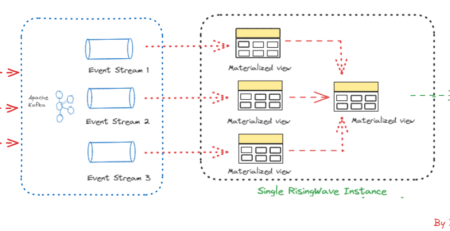
iDropper – The Data Ingestion, Monitoring and Reporting Tool
In today’s complicated world of business, the data, organizations own and how they use it, make them different from others to innovate, to compete better and to stay ahead in the business. That’s the driving factor for the organizations to collect and process as much data as possible, transform it into information with data-driven discoveries, and deliver it to the end user in the right format for smart decision-making.
Common Challenges/Concerns
- Fetching the raw data
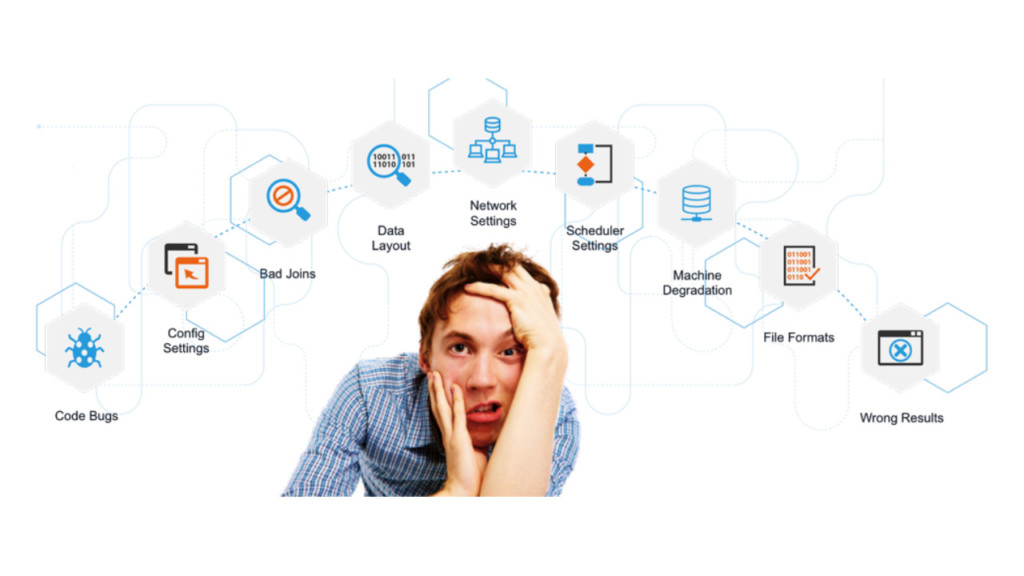 files from the various data sources (e.g. SAP, server logs, document repository etc.) and transporting them to distributed storage platforms (e.g. Hadoop Distributed File System), cloud via FTP, or traditional data warehousing systems.)
files from the various data sources (e.g. SAP, server logs, document repository etc.) and transporting them to distributed storage platforms (e.g. Hadoop Distributed File System), cloud via FTP, or traditional data warehousing systems.) - Transmitting huge volume of compressed bundle of data-files (zip or tar ball) to multi-location on multi-node cluster.
- Capturing the ingested files’ metadata such as exact time-stamp of ingestion, its size, source, destination and so on.
- Managing administrative privileges for defining, modifying and updating data-source and destination.
- Fetching only specific ones out of all the available different file patterns from remote sources, for processing them in the multi node cluster for analysis.
- Dumping raw data files of various formats to multiple locations simultaneously.
- Organizing the data files those are already present or being dumped at source, based on the file patterns and size.
- Scaling up and scaling down the watch functionality on the fly, for number of directories and file patterns.
- Too much dependency on the technical team to setup, configure data sources and destinations due to the UI interface being highly command line/script based and not user friendly.
- Use case like copying a single data file to multiple directories at the destination.
- Limited tools/components, those can perform all kind of ingestion activity independently.
- Lack of alert mechanism for Ingestion failure.
- Application submitted using Hive, Spark or MR is stuck and not progressing forward or failing after some time.
- All of sudden any application starts performing poorly.
- Not knowing what configuration parameters to change for improving performance and resource usage.
- Requirement for a self-service platform to get an idea of end-to-end behaviour of their specific applications.
Current Scenario
There are several data ingestion tools including open source available today but they are meant for specific purposes as mentioned below. To find a tool/platform which can perform all these tasks together is rare to find, which impacts the schedule, costs of implementation and integration.
- Collecting streaming/real time data e.g. log details that keep getting generated on the server, IOT devices, Twitter streaming, CDR Records, Data Generated from flight sensors etc.
- Transporting structured data from the traditional RDBMS systems to Hadoop Cluster and vice versa.
- Asynchronous Distributed Publish Subscribe model.
- There might be various licensed product suits available which can perform all above mentioned tasks together, but it comes with high cost and highly complicated and difficult to decouple and use as the difficult to configure as independent component.
And so on.
The Solution : iDropper
iDropper, the futuristic Data Ingestion Tool, not only addresses the challenges/concerns and pain points the businesses’ have, as mentioned above but goes deeper to provide the solution to the real world data ingestion issues.
iDropper ingests the legacy and enterprise data at the same time, into the distributed storage system such as HDFS, third party cloud service provider, traditional data warehousing system or even shuffling into different cluster environment. In simple terms, iDropper is the the Data Ingestion, Monitoring and Reporting Tool, that does the parallel ingestion for all kind of input data patterns efficiently.
Highlights of iDropper
The Platform
- 100% java based, and hence platform independent.
- Light weight and high on performance, as compared to other similar components/tools.
- Easy to customize and scale-up to meet customer/business’ specific demand.
- Can be integrated with elastic-search to find specific record/information from history.
- Provides clear visibility of data supplier and data processing platform.
- No specific hardware required to run iDropper.
- Designed and developed upon extensive market research and analysis of common ingestion issues, and challenges.
- Independent plug-gable component.
- Can be used as Secured File Transfer Protocol (SFTP).
User Interface
- iDropper comes with an excellent UX interface for configuring, monitoring, reporting the data-files ingestion process.
- Allows users to define the destination data lake for the data-file ingestion with minimal configuration (e.g. Hadoop cluster or any third party cloud environment.)
- Minimal or no dependency of business people on the technical team.
- Creates and manages users and role-based privileges for defining, modifying and updating data-file sources and destinations.
- Filters and migrates huge volume of heterogeneous data files from multiple data sources to a Data Lake on the fly.
- Dumping raw data files of various formats to multiple locations simultaneously.
Schedule, Monitor & Report
- On-demand extendable monitoring capability (e.g. parallel watch for multi data sources.)
- Watchdog functionality provides the exact time and size of data being ingested at destination.
- Complete control to users to restrict the ingestion for specific file patterns (i.e. .pdf, .csv, SAP, etc.).
- Batch ingestion can be configured easily.
- History of ingested data, such as, time stamp and success/failure status, is maintained and reports can be generated for businesses to review the whole ingestion process.
- Ingestion failure alert mechanism.
- A single data file can be transported to multiple directories at the configured destination.
- Organizing data files at source into different directories, based on the file patterns and size.