How to understand Data Pipeline easily
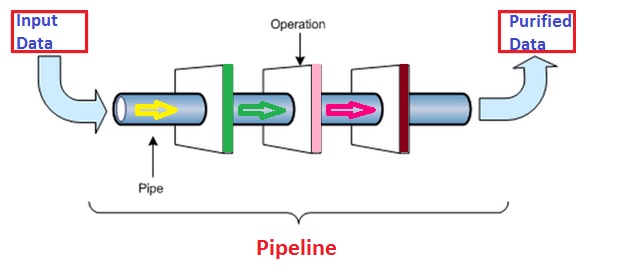
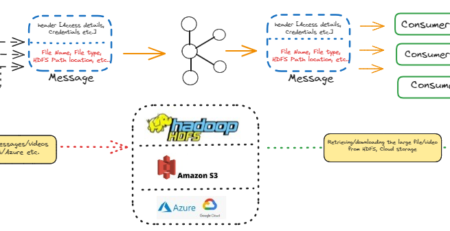
A data pipeline can be visualized as extraction, transformation and then loading of data into storage area referred as Database system or Data warehousing system. The data enters into one end of the multi-stage process in a particular shape / form and comes out of the other side in a different (desired) shape / form. The data pipeline has many stages that depends on the entered input data. There might be less number of stages if input data is quite purified and does not need more transformation. But if complex, for example unstructured data (blogs with images, emails etc). then number of stages will increase. These stages could be connecting to one or many sources of data or running in a single or multiple servers.
Now a days, Hadoop has become a popular adoption for all major organizations. We can leverage Hadoop cluster to build a data pipeline for the purpose of extraction, loading and then transformation. Hadoop platform provides a highly scalable and fault tolerance infrastructure which is built on cheap commodity hardware. Infact, if we need to extract a specific information from millions of tweets in tweeter streaming, we need to have data pipeline because data supply from tweeter is unstructured.