Forging Apache Druid with Apache Kafka for real-time streaming analytics
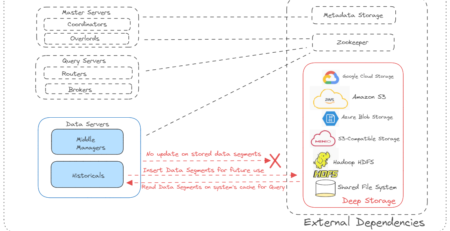
A real-time analytics database called Apache Druid is developed for quick slice-and-dice analysis on massive data volumes. The best data for Apache Druid is event-oriented and frequently utilized as the database backend for analytical application GUIs and for highly concurrent APIs that require quick aggregations. Druid can be leveraged very effectively where real-time ingestion, fast query performance, and high uptime are crucial.
At the other end, Apache Kafka is gaining outstanding momentum as a distributed event streaming platform with excellent performance, low latency, fault tolerance, and high throughput and having capable of handling thousands of messages per second.
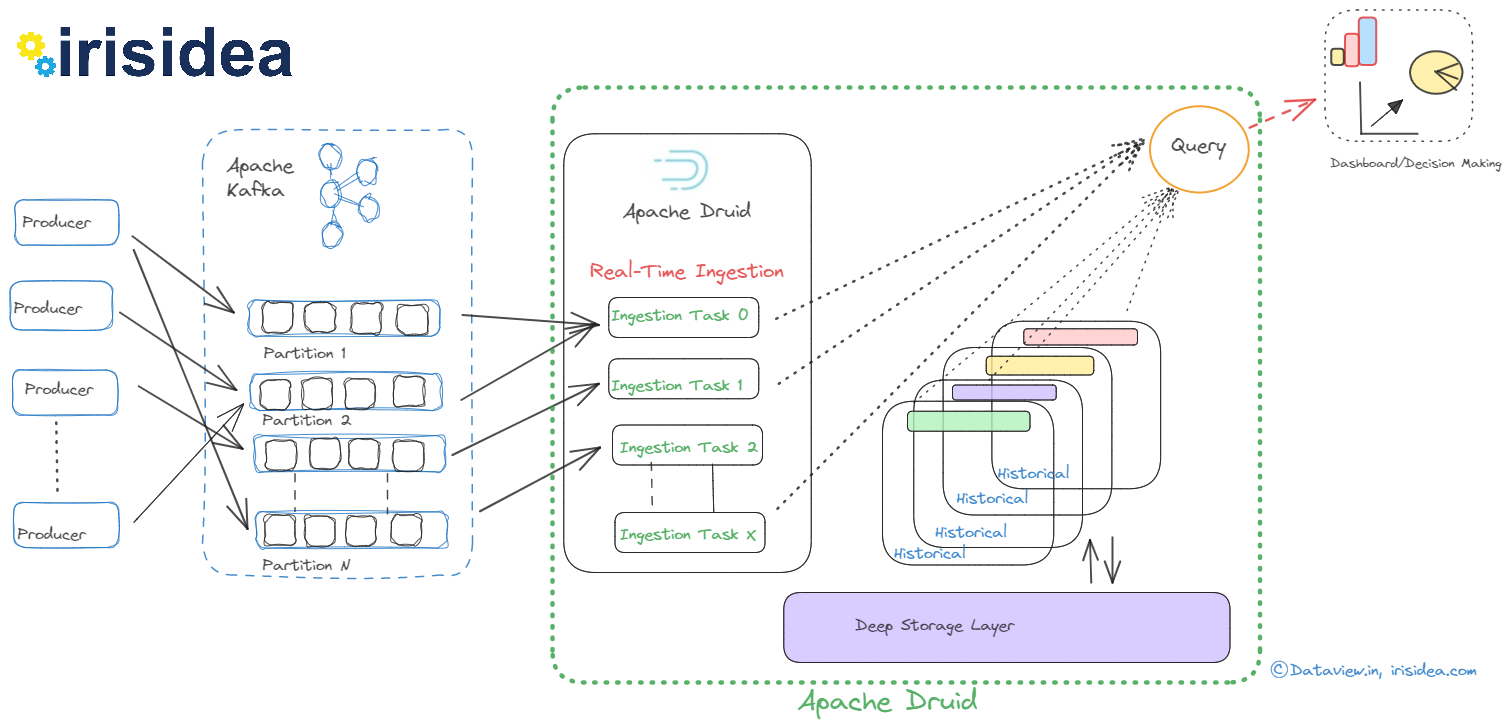
However, there are multiple steps to be crossed to visualize/analyze eventually for achieving the business goal/decision from real-time data streaming that is ingested to Kafka continuously from various live data sources. As a bird’s eye view, these steps can be outlined as
- Consume data from Kafka’s topic by subscribing to it and execute various data pipelines subsequently for transformation, validation, cleansing, etc before dumping into a permanent repository/database for the query.
- By integrating different types of Kafka connectors (like JDBC Kafka Sink Connector), data can be pulled out from Kafka’s topic and pushed to RDBMS/repository for query, visualization, etc. But there is a Schema Registry dependency while using JDBC Kafka Sink Connector.
- Confluent REST proxy too can be leveraged for consuming the messages/data from the Kafka topic directly and persist into RDBMS via adapters.
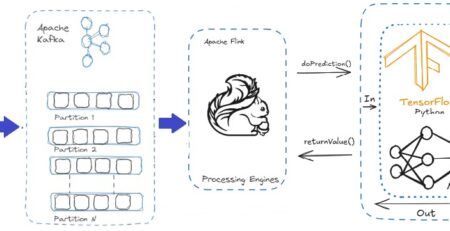
But with Apache Druid, we can directly connect Apache Kafka so that real-time data can be ingested continuously and subsequently queried to take business decisions on the spot without interventing any third-party system or application. Another beauty of Apache Druid is that we need not configure or install any third-party UI application to view the data that landed or is published to the Kafka topic.
In this article, we are going to see the steps of how Apache Druid can be installed, configured with a single-node Apache Kafka cluster, and stream/publish a few String data using Kafka’s built-in console producer and eventually visualize in Apache Druid.
Assumptions:-
- The system has a minimum of 8 GB RAM and 250 GB SSD along with Ubuntu-22.04.2 amd64 as the operating system.
- OpenJDK 11 is installed with JAVA_HOME environment variable configuration.
- Python 3 or Python 2 along with Perl 5 is available on the system.
- Single-node Apache Kafka-2.7.0 cluster has been up and running with Apache Zookeeper -3.5.6. (Please read here how to set up a multi-node Kafka cluster)
Installation -> Configuration -> Start:-
- The latest version of Apache Druid can be downloaded from https://www.apache.org/dyn/closer.cgi?path=/druid/26.0.0/apache-druid-26.0.0-bin.tar.gz
- Open a terminal and extract the downloaded tarball. Change directories to the distribution directory.
- Stop the Kafka broker along with Zookeeper if already running.
- Apache Druid is too dependent on Zookeeper so we can leverage the same Zookeeper instance that is already bundled and configured with Druid for Kafka broker to run. We can abandon the previous Zookeeper instance that was running with Kafka broker. We can switch over to this zookeeper instance again when we won’t run the Druid instance.
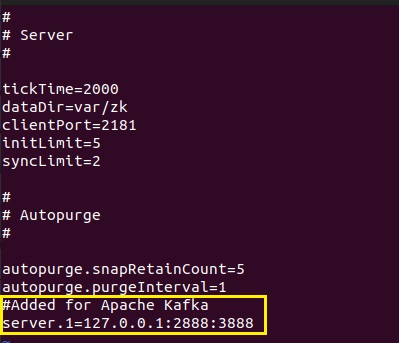
- Navigate to the zoo.cfg file available under /apache-druid-26.0.0/conf/zk and add the following
Server.1=127.0.0.1:2888:3888
6. Open a terminal and navigate to /apache-druid-26.0.0/bin and execute ./start-druid
The following should appear on the terminal
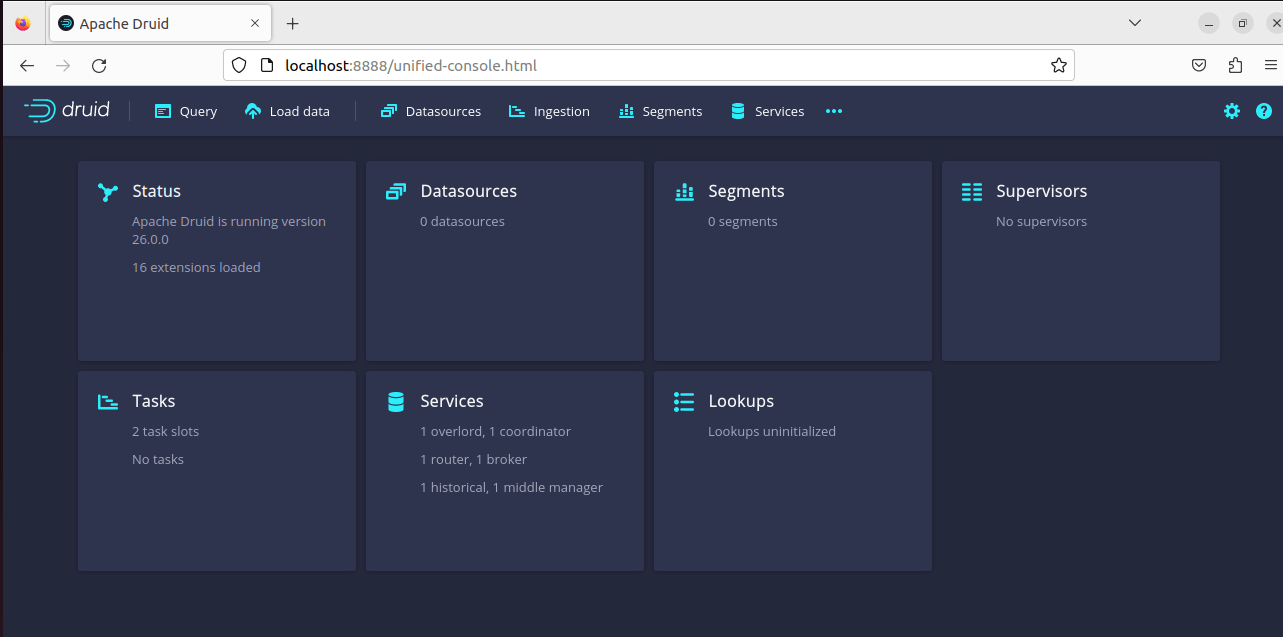
7. Open a browser (Probably an updated version of Firefox, by default available with Ubuntu 22.04) and type the URL as http://localhost:8888. Follow page should be displayed on the browser
8. Start the Kafka broker and create a new topic as FirstTopic using the kafka-topic.sh from a terminal. (You can read here how to create a topic using the built-in script)
9. Click on “Streaming” by navigating through the “Load Data” menu on the browse. And subsequently, start a “Start a new streaming spec”
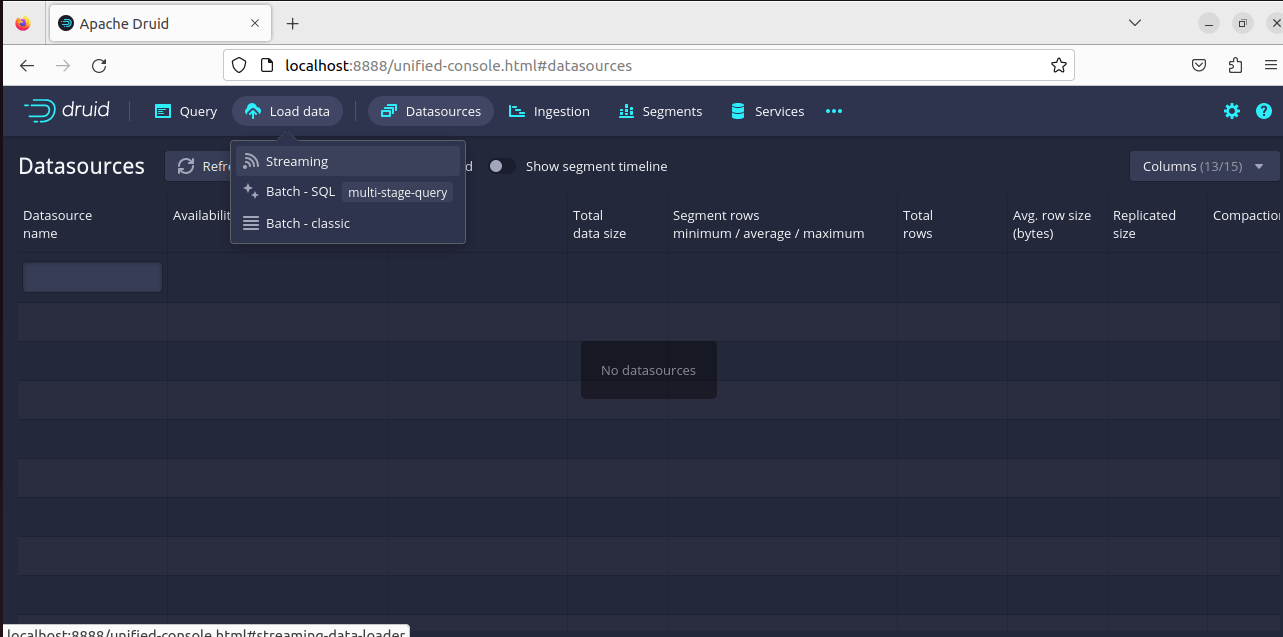
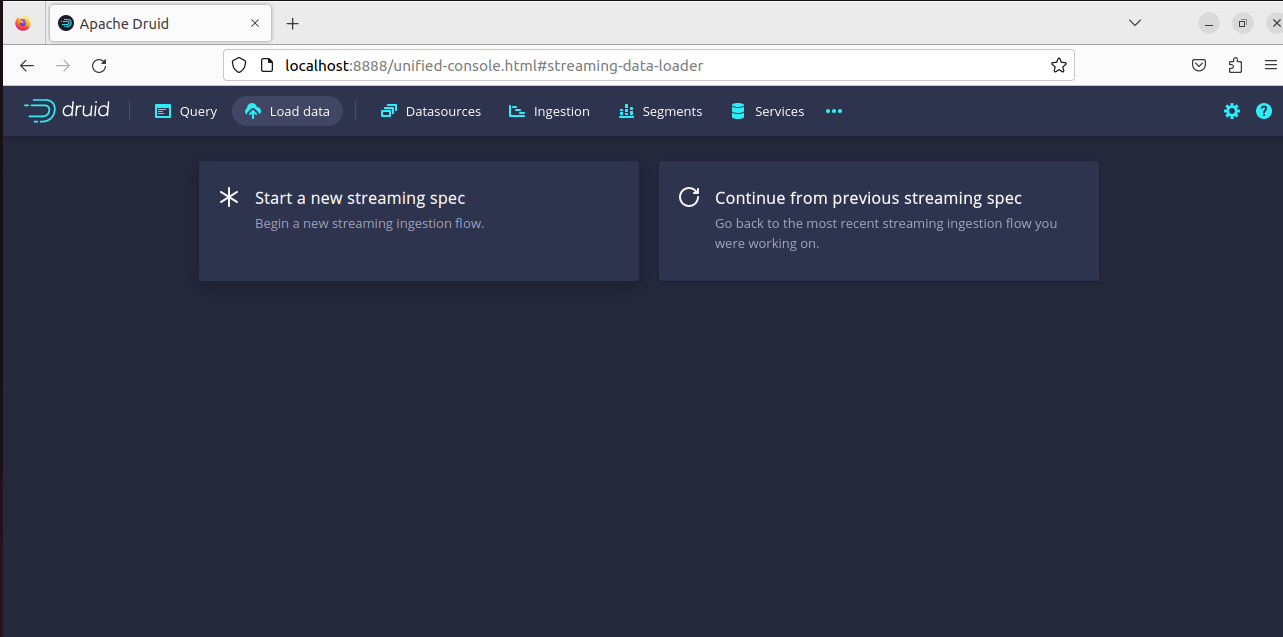
10. Click on Apache Kafka
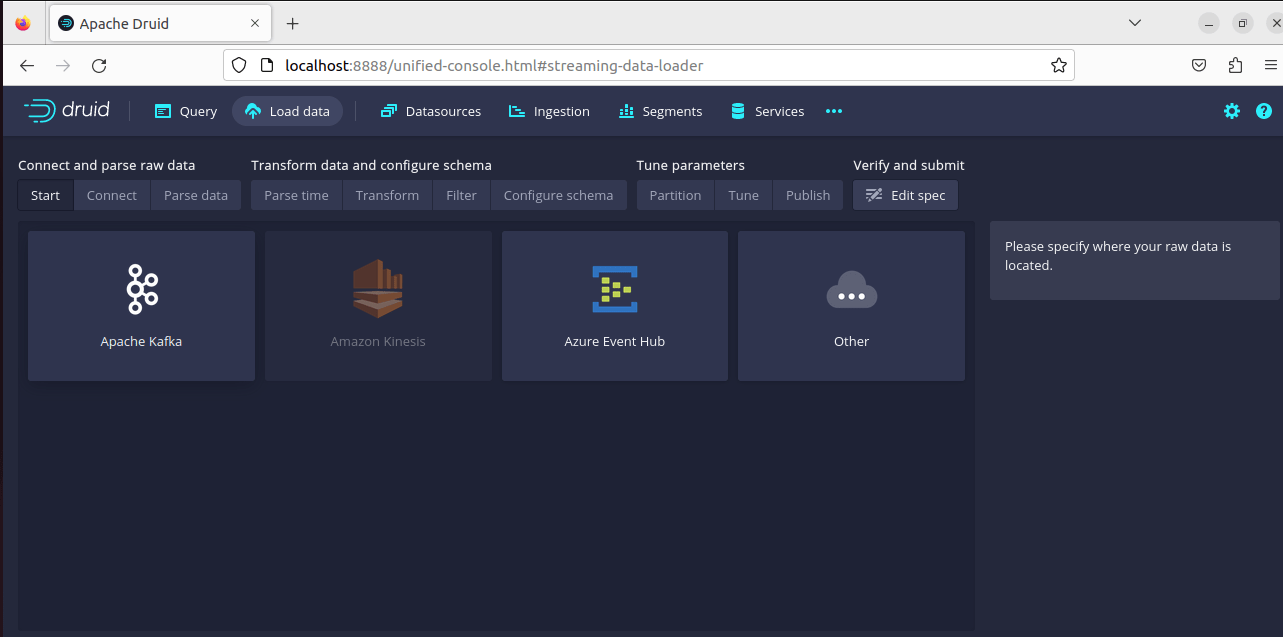
11. Update the Bootstrap servers as “localhost:9092” and Topic as “FirstTopic”. Druid would fetch the real-time data from this topic once data/message is published to Kafka’s topic “FirstTopic”. Click on the “Start of stream” radio button and eventually the “Start” button.
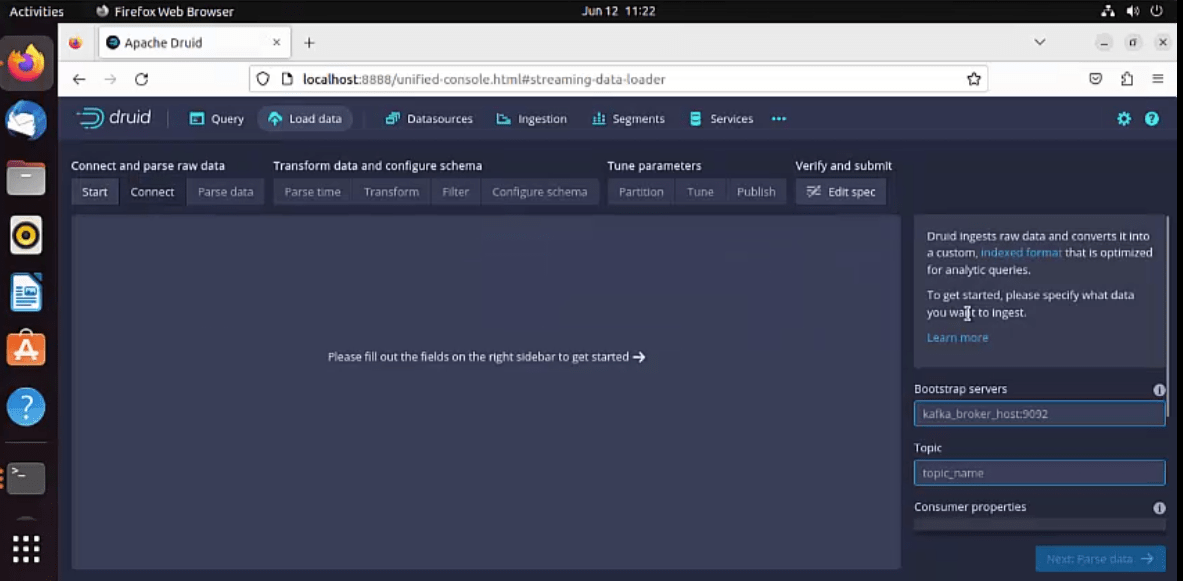
12. Execute the built-in console producer script available inside Kafka’s bin directory and start publishing a few messages/data into “FirstTopic”.
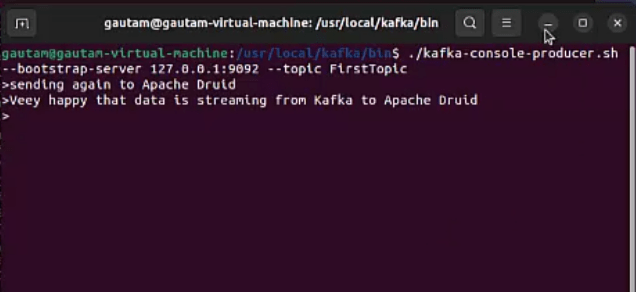
13. Click on “Next Parse Data” and proceed to the “ Parse Data” tab on the browser, the messages/data would be displayed immediately with a timestamp.
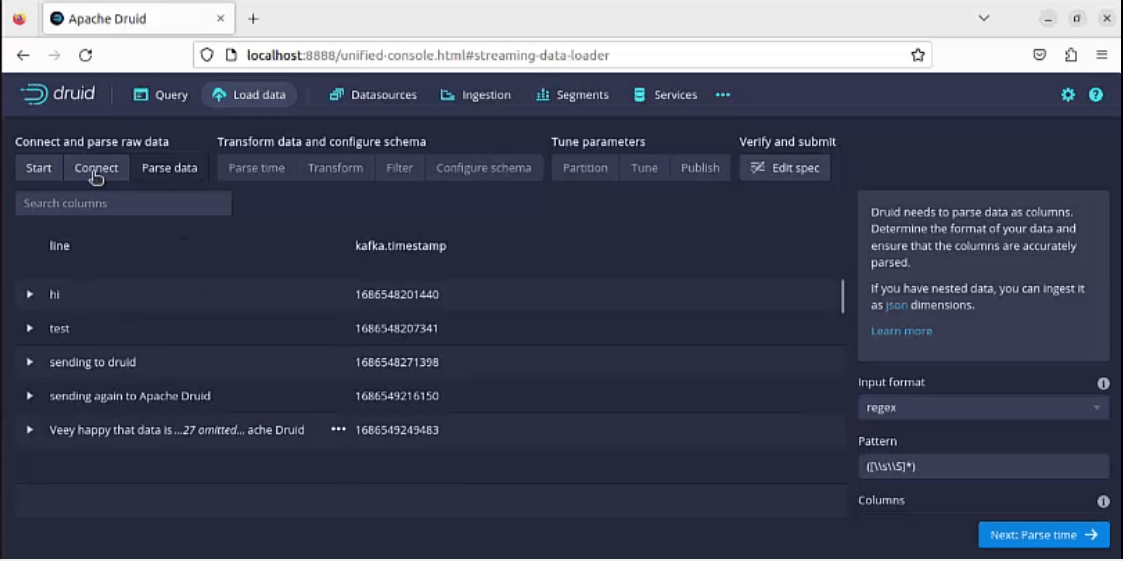
There are many other options available to set the input format, Patterns, etc. Will explain in upcoming articles related to Druid’s outstanding features.
To know more about Druid, you can visit https://druid.apache.org
Below, you could watch the short video that has been captured while performing the above.
References:- https://druid.apache.org/docs/latest/design/index.html
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable. Watch this space for additional articles on handling real-time data streaming.
By Gautam Goswami