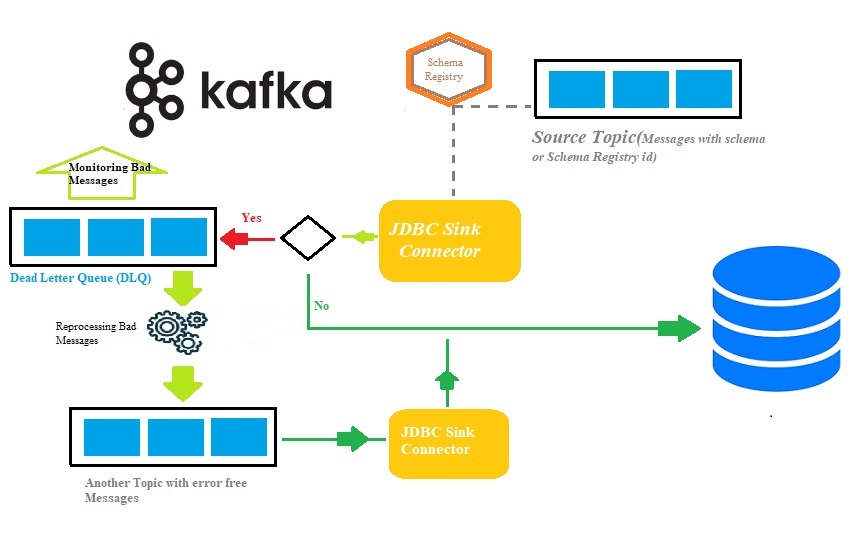
Handling bad messages via DLQ by configuring JDBC Kafka Sink Connector
Any trustworthy data streaming pipeline needs to be able to identify and handle faults. Exceptionally while IoT devices ingest endlessly critical data/events into permanent persistence storage like RDBMS for future analysis via multi-node Apache Kafka cluster. (Please click here to read how to setup multi-node Apache Kafka Cluster). There could be scenarios where IoT devices might send fault/bad events due to various reasons at the source points and henceforth appropriate actions can be executed to correct it further. The Apache Kafka architecture does not include any filtering and error handling mechanism within the broker so that maximum performance/scale can be yielded. Instead, it is included in Kafka Connect which is an integration framework of Apache Kafka. As a default behavior, if a problem arises as a result of consuming an invalid message, the Kafka Connect task terminates and the same applies to JDBC Sink Connector.
Kafka Connect has been classified into two categories namely Source (to ingest data from various data generation sources and transport to the topic) and Sink (to consume data/messages from the topic and send them eventually to various destinations). Without implementing a strict filtering mechanism or exception handling, we can ingest/publishes messages inclusive of wrong formatted to the Kafka topic because the Kafka topic accepts all messages or records as byte arrays in key-value pairs. But By default, the Kafka Connect task stops if an error occurs because of consuming an invalid message, and on top of that JDBC sink connector additionally won’t work if there is an ambiguity in the message schema.
The biggest difficulty with the JDBC sink connector is that it requires knowledge of the schema of data that has already landed on the Kafka topic. Schema Registry must therefore be integrated as a separate component with the exiting Kafka cluster to transfer the data into the RDBMS. Therefore, to sink data from the Kafka topic to the RDBMS, the producers must publish messages/data containing the schema. You could read here to know for streaming Data via Kafka JDBC Sink Connector without leveraging Schema Registry from Kafka topic.
Since Apache Kafka 2.0, Kafka Connect has integrated error management features, such as the ability to reroute messages to a dead letter queue. In the Kafka cluster, a dead letter queue (DLQ) is a straightforward topic that serves as the destination for messages that, for some reason, were unable to reach their intended recipients, especially for JDBC sink connector, tables in RDBMS
There might be two major reasons why the JDBC Kafka sink connector stops working abruptly while consuming messages from the topic
– Ambiguity between data types and the actual payload
– Junk data in payload or wrong schema
There is no complicacy of DLQ configuration in the JDBC sink connector. The following parameters need to be added in the sink configuration file (.properties file).
errors.tolerance=all
errors.deadletterqueue.topic.name= <<Name of the DLQ Toic>>
errors.deadletterqueue.topic.replication.factor= <<No of replication>>
Note:- No of replication should be equal or less then the number of Kafka broker in the cluster.
The DLQ topic would be created automatically with the above-mentioned replication factor when we start the JDBC sink connector for the first time. When an error occurs or bad data is encountered by the JDBC sink connector while consuming messages from the topic, these unprocessed messages/bad data would be forwarded straightly to the DLQ. Subsequently, correct messages or data will send to the respective RDBMS tables continuously, and again in between if bad messages are encountered then the same would be forwarded to the DLQ and so on.
After landing the bad or erroneous messages on the DLQ, we will have two options either manually introspect each message to understand the root cause of the error or implement a mechanism to reprocess the bad messages and push them eventually to the consumers, for JDBC sink connector the destination should be RDBMS tables. Dead letter queues are not enabled by default in Kafka Connect due to the above reason. Even though Kafka Connect supports several error-handling strategies, such as dead letter queues, silently ignoring, and failing quickly, the adoption of DLQ would be the best approach while configuring the JDBC sink connector. Decoupling completely the bad/error messages handling from the normal messages/data transportation from the Kafka topic would boost the overall efficiency of the entire system as well as allow the development team to develop an independent error handling mechanism from easy maintainability perspectives.
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable.
Written by
Gautam Goswami