10Apr
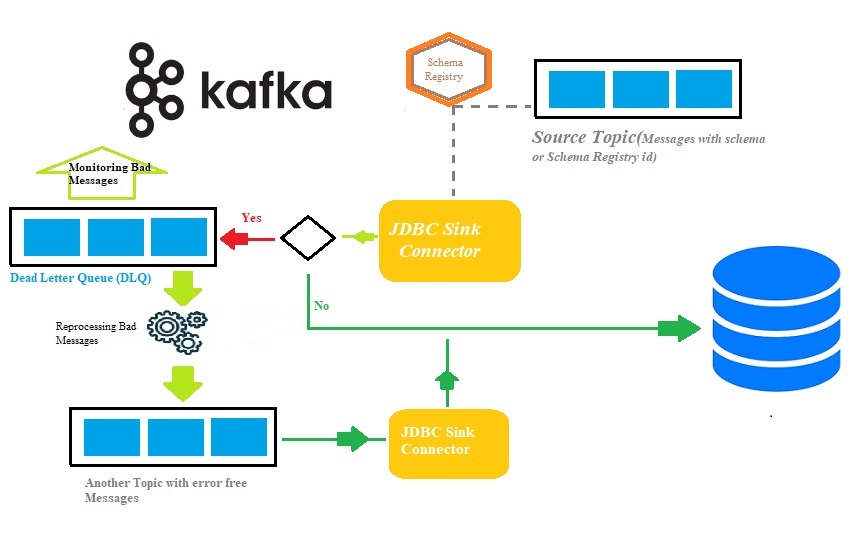
Handling bad messages via DLQ by configuring JDBC Kafka Sink Connector
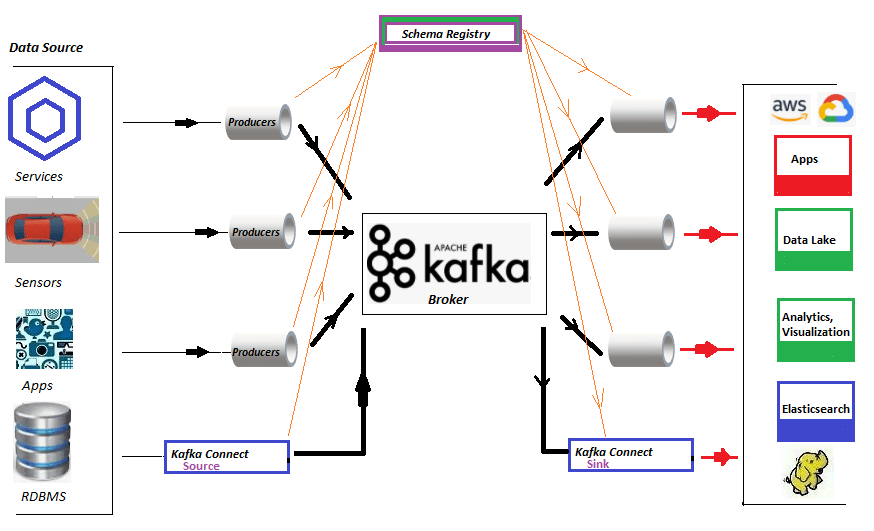
Any trustworthy data streaming pipeline needs to be able to identify and handle faults. Exceptionally while IoT devices ingest endlessly critical data/events into permanent persistence storage like RDBMS for future analysis via multi-node Apache Kafka cluster. (Please click here to read how to setup multi-node Apache Kafka Cluster). There could be scenarios where IoT devices might send fault/bad events due to various reasons at the source points and henceforth appropriate actions can be executed to correct it further. The Apache Kafka...