Crafting a Multi-Node Multi-Broker Kafka Cluster- A Weekend Project
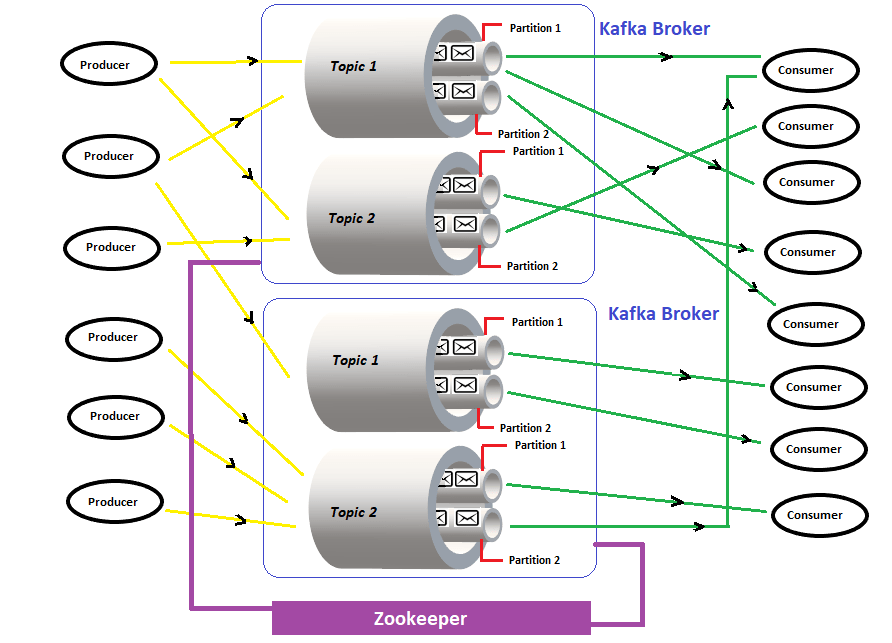
For the past couple of years, there has been a huge development in the appropriation of Apache Kafka. Kafka is a scalable pub/sub system and in a nutshell, is designed as a distributed multi-subscription system where data persists to disks. On top of it as a highlight, Kafka delivers messages to both real-time and batch consumers at the same time without performance degradation. Current users of Kafka incorporate Uber, Twitter, Netflix, LinkedIn, Yahoo, Cisco, Goldman Sachs, and so forth. Can refer here to know about Apache Kafka
This article aims to explain the steps of how we can install and configure the multi-node multi-broker Kafka cluster where Ubuntu 14.04 LTS as an OS on all the nodes in the cluster. Multi-node Kafka cluster provides better reliability and high availability of the Kafka service. Install and running a single Kafka broker is possible but we can’t achieve all the benefits that a Multi-node Kafka cluster can give, for example, data replication.
Article Structure
This article has structured in four parts:
- As a beginning, I will start with the assumption on the multi-node cluster w.r.t installed software and configurations.
- Install Kafka and subsequent configuration on all the nodes in the cluster.
- Run and verify the setup
- The code snippet in java to write and consume messages from specific partition in a designated topic
Assumptions:
Here I am considering three nodes physically separated from each other in the cluster and each system is already loaded with OS Ubuntu 14.04 LTS.
- SSH connection has been installed and configured among the three nodes. Please refer here to know more about how to enable SSH on Ubuntu.
- Java 8+ has been downloaded and installed on all the nodes.
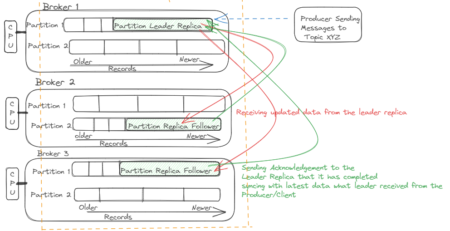
- Zookeeper installed, configured in all the nodes on the cluster, and running successfully with a leader and follower mode. Zookeeper is mandatory and holding the main responsibility of keeping the information on the broker, topic, and partition for each Kafka node.
- Kafka Controller maintains leadership through Zookeeper. Please refer here to set up a multi-node Zookeeper cluster.
- Not configuring Schema Registry
Installation and configuration of Kafka
Downloaded Apache Kafka of version 2.3.1 from Apache Download mirror and extracted the tar ball.

After extraction, the entire directory “kafka_2.11-2.3.1” moved to /usr/local/kafka. Make sure we should have “root” privilege.
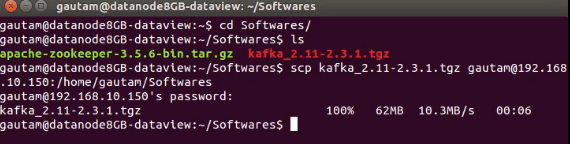
Once above steps completed in one node, repeat the same on other remaining nodes in the cluster. We can scp the entire extracted directory “ kafka_2.11-2.3.1″ or the downloaded kafka_2.11-2.3.1.tgz.
As a configuration step, navigate to “config” directory available inside “/usr/local/kafka” and open the server.properties in vi editor to manipulate/update key value pair. The following keys should have the corresponding values.

- broker.id . This key should be assigned with unique integer number that denotes as id of the broker in the cluster. Since we have 3 nodes in the cluster, so set value as 1,2 and 3 for each broker.

- log.dirs. The value for this key is the location directory where Kafka logs will be stored. For each node, we created the log directory and updated the location/path.

- num.partitions. The concurrency mechanism in Kafka is achieve by partitions. A topic in Kafka is divided into 1 or more partitions or we can say
Kafka topics are divided into a number of partitions. According to LinkedIn, the calculation use to optimize the number of partitions for a Kafka implementation is
# Partitions = Desired Throughput / Partition Speed
Please visit here to read more about Kafka optimization partition calculation. Since our number of nodes in the cluster is less and intended to consume and produce very less message so we set the value as 5. You can set it as 1 if considering the cluster for leaning purposes.

There is an option to increase or decrease the number of partitions in a specific topic in the configured/running Kafka cluster. Here is the command to execute that inside the bin directory of Kafka.
bin/kafka-topics.sh –alter –zookeeper <IP address of each zookeeper node separated by comma with port no> –topic <Topic Name> –partitions <Number of partition>
For example
bin/kafka-topics.sh –alter –zookeeper 192.168.10.130:5181, 192.168.10.150:5181, 192.168.10.110:5181 –topic MultinodeTest –partitions 5
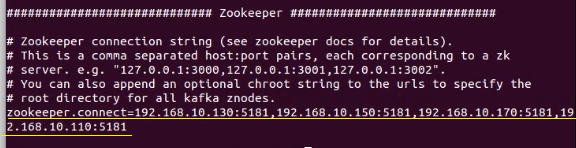
- zookeeper.connect. The value of this key is the list of zookeeper servers IP address and port separated by comma (,)
- delete.topic.enable=true. By default, this key-value pair won’t be available in server.properties, we have to explicitly add this to delete the created topic.

The rest of the key-value pairs we won’t modify since they are mostly related to the production environment. Repeated the above changes on the other two remaining nodes in the cluster.
Now, a topic needs to be created on each node in the cluster and can be done by executing the following command inside bin directory available under the home directory of Kafka.
bin$ ./kafka-topic.sh –create –zookeeper <list of zookeeper server IP address with port separated by comma > –replication-factor 3 –partition 5 –topic <topic name>

Replication factor defines the number of copies of data or messages over multiple brokers in a Kafka cluster. The replication factor value should be greater than 1 always (between 2 or 3).
Run and verify the Cluster
Before starting the Kafka server that is installed and configured on each node in the cluster, we need to make sure the zookeeper server on each node is running successfully.
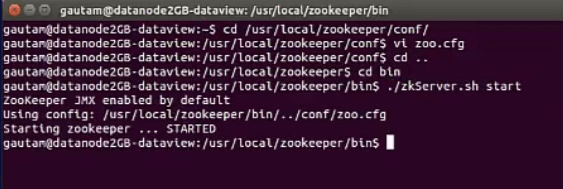
Once zookeeper servers up and running in the entire cluster, let’s navigate to bin directory available inside the home directory of Kafka on each node and execute the command as
bin$ ./kafka-server-start.sh ../config/server.properties

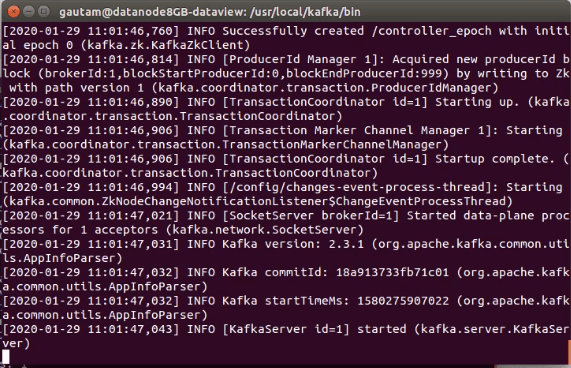
We can verify the log file for any error after starting of each Kafka server in the cluster.
To verify the entire Kafka cluster without developing and running an explicit producer, consumer program, quickly we can execute console producer and consumer script to send some dummy messages as well as consume subsequently. The scripts kafka-console-producer.sh and kafka-console-consumer.sh are available inside the bin directory. To send messages into multiple brokers at a time
/kafka/bin$ ./kafka-console-producer.sh –broker-list <<IP Addresses and port separated by comma (,) >> –topic <<Topic Name>>

Similarly, to consume those sent messages from a particular broker’s topic
/kafka/bin$ ./kafka-console-consumer.sh \–bootstrap-server <<IP Address and port of a node/broker>> \– topic <<Topic Name>> \–from-beginning
Code snippet in java
Here are the few lines of code of a producer to send messages into a specific partition of a Topic
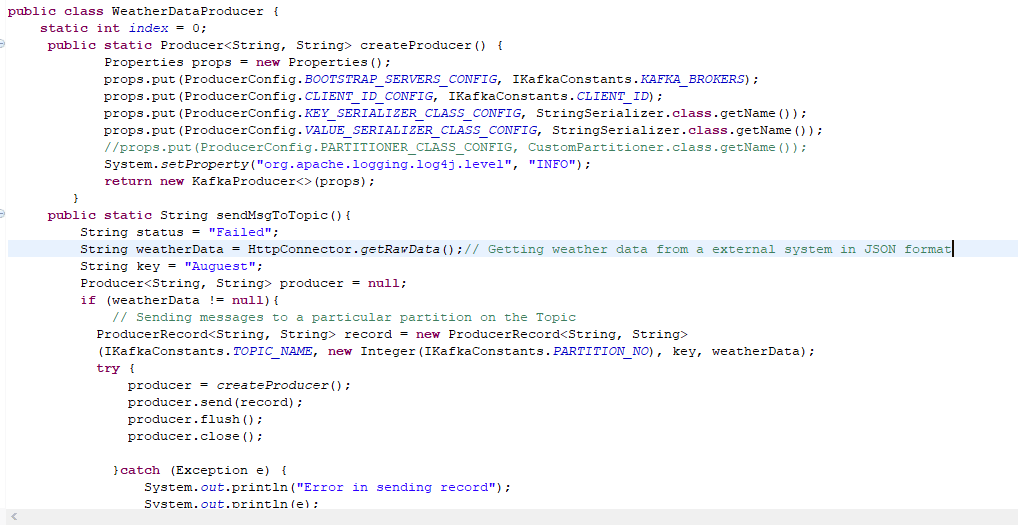
as well as consumer code to read the messages from the particular partition of a topic.
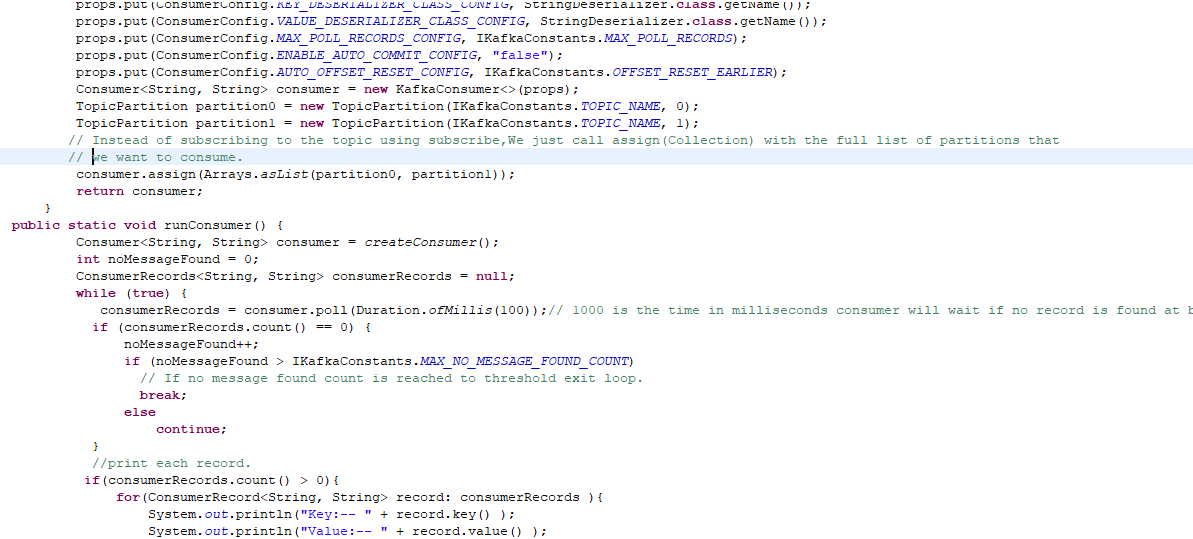
The above code snippet is just for a better understanding of how to produce and consume messages programmatically to a specific partition.
Hope you have enjoyed this read. You can try in AWS EC2 Linux instances if hardware infrastructure is not available.
Written by
Gautam Goswami