Architecture to leverage Apache Kafka for sharing large messages (GB size)
In today’s data-driven world, the capability to transport and circulate large amounts of data, especially video files, in real-time is crucial for news media companies. For example, an incident occurred in a specific location, and a news reporter promptly filmed the entire situation. Subsequently, the complete video was distributed for broadcasting across their multiple studios situated in geographically distant locations.
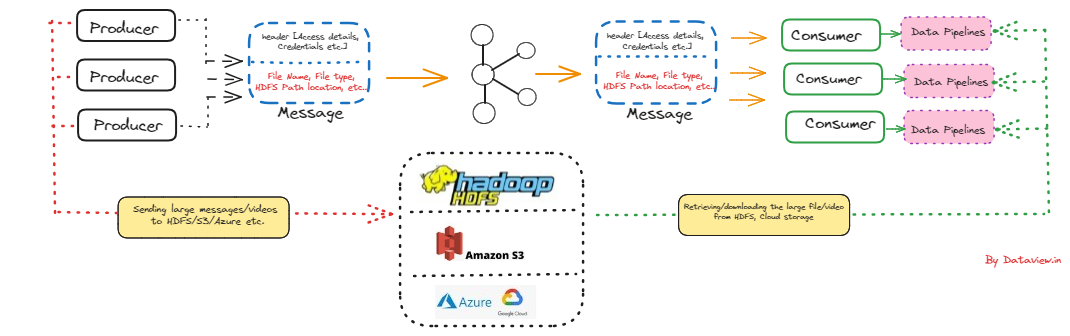
To construct or create a comprehensive solution for the given problem statement, we can utilize Apache Kafka in conjunction with external storage to upload large-sized video files. The external storage may take the form of a cloud store, such as Amazon S3, or an on-premise large file storage system, such as a network system or HDFS (Hadoop Distributed File System). Of course, Apache Kafka was not designed for handling large data files as direct messages for communication between publishers and subscribers/consumers. Instead, it serves as a modern event streaming platform where, by default, the maximum size of messages is limited to 1 MB.
There are several reasons why Kafka has limited the message size by default. One of the major reasons is the large messages are expensive to handle, could slow down the brokers, and eventually increase the memory pressure on the broker JVM.
In this article, we will explore the architectural approach for separating the actual payload (the large video file) from the message intended to be circulated via Kafka. This involves notifying subscribed consumers, who can then proceed to download the video files for further processing or broadcast after editing.
The first thing that should cross our mind is that databases don’t recognize video files. There is no “image” or “video” data type. This is why we will have to manually convert video files into blobs and manage them ourselves in whatever format we choose (base64, binary, etc.). This is an extra operation that needs to be handled each time we do any transaction with the large video files.
To mitigate the former obstacle as said with the database, we can store large video files on a distributed file system like HDFS or Hadoop Distributed File System. When we want to store a large file, it gets broken into blocks and it gets replicated across the cluster. This redundancy is very helpful to increase data availability and accessibility. An on-premise large file storage system such as a network system or HDFS would be the best option if we don’t rely on cloud storage such as Amazon S3 or Microsoft Azure because of cost/revenue constraints.
The data is kept on HDFS in blocks of a predetermined size (default 128MB in Hadoop 2.X). Although the entire files are seen when using the hdfs and dfs commands, HDFS internally saves these files as blocks. In a nutshell, we could mount a remote folder/location where large video files can be dumped, and subsequently by executing a script periodically, those files can be transferred into HDFS. The script might internally use distcp, a general utility for copying large data sets between remotely mounted folder location and the HDFS cluster’s folder location for storage.
Once the file is stored successfully on HDFS cluster, the location of the HDFS folder with the file name can be clubbed together with access details of the HDFS cluster like IP address, security credentials, etc in Kafka message via Kafka publisher and eventually published to the Kafka topic.
The message structure could be like below
{
“headers”: {
“Content-Type”: “application/json”,
“Authorization”: “Authorization token like eyJhb$#@67^EDf*g&”,
“Custom-Header”: “some custom value related to video”
},
“key”: “Key of video file like name of the file”,
“value”: {
“field1”: “video file extension like mp4, avi etc”,
“field2”: “Location of HDFS folder where video file has been uploaded like
hdfs://Remote-namenode:8020/user/sampleuser/data/videos/news.mp4″
}
}
On the other hand, the consumers subscribed to that topic can consume these messages and extract the file location where the large video file has been uploaded on the remote HDFS cluster. We might need to integrate different downstream data pipelines with the consumers to execute the workflow to download the video file from the HDFS cluster into the local system. Typically, to download a file from the Hadoop Distributed File System (HDFS) to the local system, we can use the hadoop fs command or the distcp (distributed copy) command. We can also use a tool like Apache Nifi to transfer data from HDFS to a local filesystem. Once the video file is available in the geographically separated location, the same can be edited/modified and finally can be broadcast via various news channels.
In summary, this represents a high-level architectural concept leveraging Apache Kafka to inform subscribed message consumers about the upload of a large video file to remote big data storage, including all relevant credentials and the file’s location. By processing these events through integrated downstream data pipelines, consumers can download and process the large video file, preparing it for subsequent broadcasting. However, it’s important to acknowledge potential gray areas or challenges in the discussed approach that may emerge during the detailed implementation.
I hope you enjoyed reading this. If you found this content valuable, please consider liking and sharing.
By Gautam Goswami