01Jun
Knowing and valuing Apache Kafka’s ISR (In-Sync Replicas)
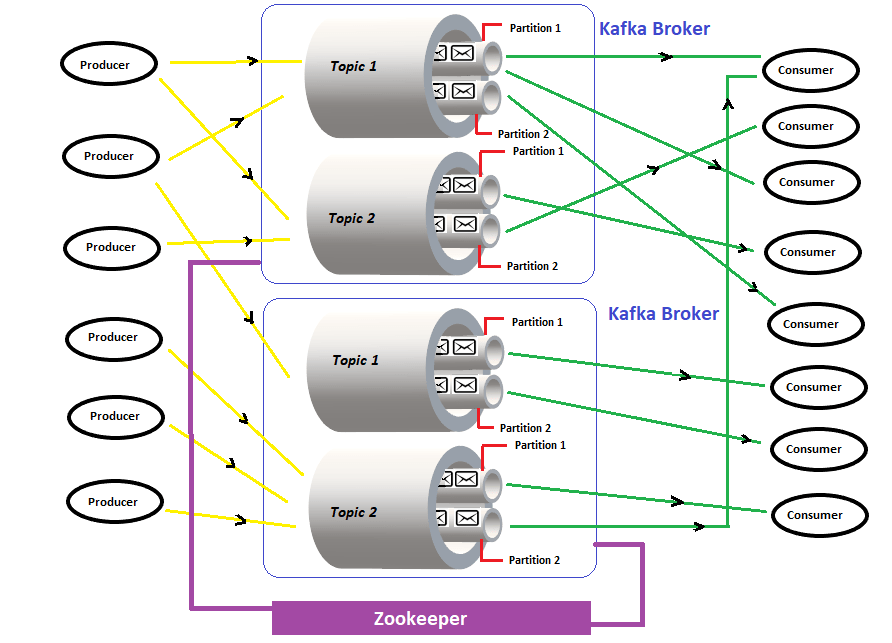
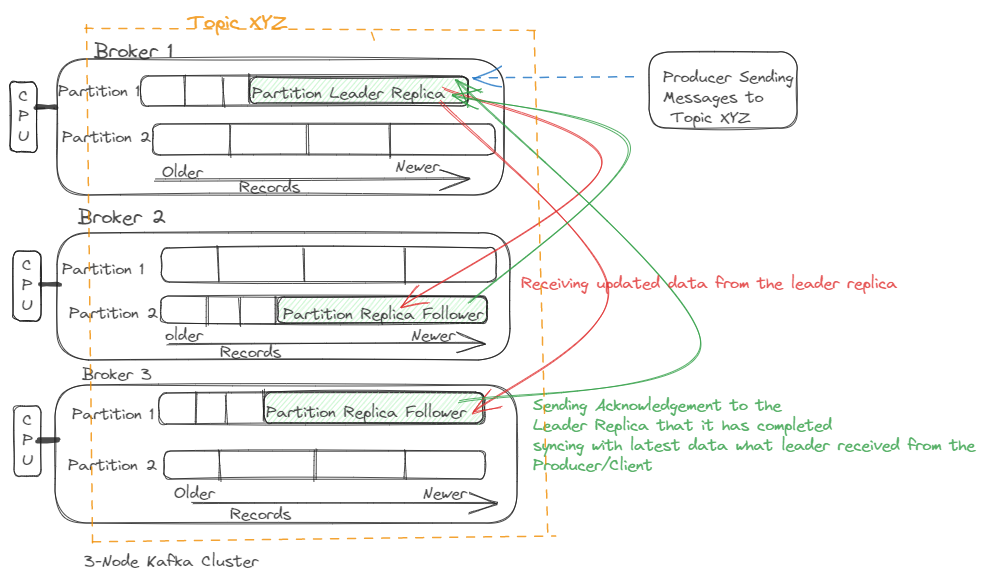
To get more clarity about ISR in Apache Kafka, We should first carefully examine the replication process in the Kafka broker. In short, replication means having multiple copies of our data spread across multiple brokers. Maintaining the same copies of data in different brokers makes possible the high availability in case one or more brokers go down or are untraceable in a multi-node Kafka cluster to server the requests. Because of this reason, it is mandatory to mention how...