How Kafka Works?
#realtimedata streaming with #kafka is a popular and powerful approach to handle large volumes of data and facilitate communication between different systems and applications. #apachekafka is an open-source distributed event streaming platform that allows you to publish, subscribe, store, and process streams of records.
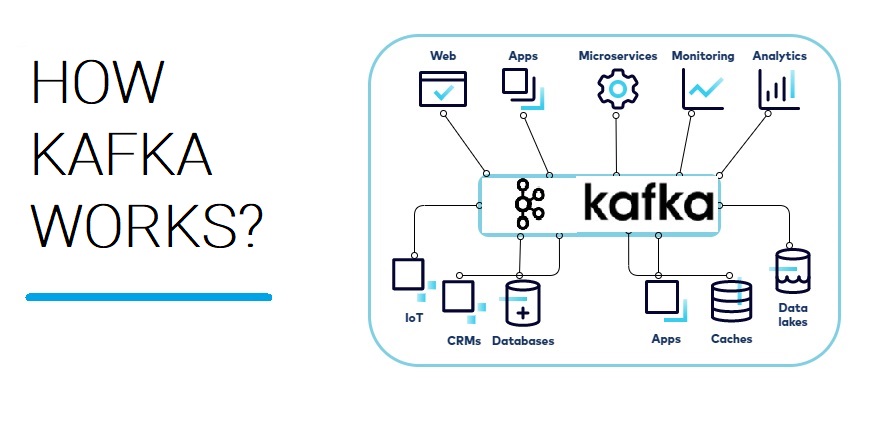
Here’s a general overview of how real-time data streaming with Kafka works:
Topic and Message Model:
Data is organized into topics, which are essentially log-like data streams.
Each message within a topic consists of a key, value, and timestamp.
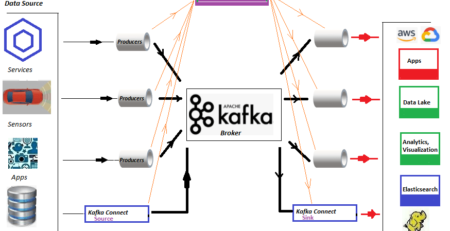
Publishers (Producers):
Data producers, also known as publishers or producers, send messages to Kafka topics.
Producers decide which topic a message should be published to.
Kafka Cluster:
Kafka is designed to be distributed and scalable. It consists of a cluster of brokers, where each broker is a Kafka server responsible for handling incoming data and maintaining the data partitions.
Consumers (Subscribers):
Data consumers, also known as subscribers or consumers, read messages from Kafka topics.
Consumers can subscribe to one or more topics and receive real-time updates as new messages arrive.
Consumer Groups:
Kafka allows consumers to form consumer groups.
Each consumer group can have multiple consumers, but each partition of a topic can be consumed by only one consumer within a group at a time.
This allows for parallel processing and load balancing across consumers.
Retention and Storage:
Kafka retains messages for a configurable period of time, allowing consumers to replay messages if needed.
The messages are stored on disk, making Kafka suitable for both real-time and historical data processing.
Scalability and Fault Tolerance:
Kafka’s distributed nature and replication mechanism provide high availability and fault tolerance.
Brokers can be added or removed to scale the system as needed.
Real-time data streaming with Kafka finds applications in various scenarios, such as log aggregation, event-driven architectures, stream processing, metrics monitoring, and more. Kafka’s robustness, scalability, and performance make it an excellent choice for handling large-scale data streams in real time.
To work with Kafka, you’ll typically need to use a client library or connector in the programming language of your choice.
Some popular programming languages and frameworks for Kafka integration include #java #python , Apache Kafka Streams, #apacheflink , and #ApacheSpark. These libraries provide APIs to publish messages to Kafka topics, consume messages from topics, and perform stream processing operations.
Always remember to design your Kafka architecture carefully and consider factors like message retention policy, partitioning, and replication to ensure a reliable and efficient data streaming system.
To see how Apache Kafka can be instrumental for your data streaming problems of your business, collaborate with team #irisidea.