Streaming Data to RDBMS via Kafka JDBC Sink Connector without leveraging Schema Registry
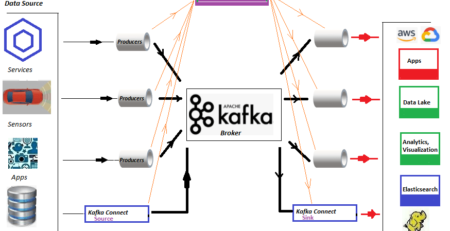
In today’s M2M (Machine to machine) communications landscape, there is a huge requirement for streaming the digital data from heterogeneous IoT devices to the various RDBMS for further analysis via the dashboard, triggering different events to perform numerous actions. To support the above scenarios Apache Kafka acts like a central nervous system where data can be ingested from various IoT devices and persisted into various types of the repository, RDBMS, cloud storage, etc. Besides, various types of data pipelines can be executed before or after data arrives at Kafka’s topic. By using the Kafka JDBC sink connector, we can streaming data continuously from Kafka’s topic into respective RDBMS.
The biggest difficulty with the JDBC sink connector is that it requires knowledge of the schema of data that has already landed on the Kafka topic. Schema Registry must therefore be integrated as a separate component with the exiting Kafka cluster in order to transfer the data into the RDBMS. Therefore, to sink data from the Kafka topic to the RDBMS, the producers must publish messages/data containing the schema. The schema defines the structure of the data format. If the schema is not provided, JDBC sink connector would not be able to map the messages with the database table’s columns after consuming messages from the topic.
By leveraging Schema Registry, we can avoid sending schema every time with messages/payloads from the producers because Schema Registry stores or registers schemas in _schemas topic and bind accordingly with the configured/mentioned topic name as defined in the JDBC sink connector’s properties file. Please click here to read how Confluent’s Schema Registry can be integrated with operation multi-node Apache Kafka Cluster
The licensing cost might be the hurdle for small or medium size companies who wish to use Oracle or Confluent’s Schema Registry with open source Apache Kafka to gather IoT device data for their business perspectives.
In this article, we are going to see using Java code snippet how data can be streamed continuously into MySQL database from Apache Kafka topic by using JDBC Sink connector without Schema Registry.
Apache Kafka has not bundled the JDBC connectors for vendor-specific RDBMS similar to File source and sink connectors. It’s our responsibility to implement or develop the code for specific RDBMS by implementing Apache Kafka’s Connect API . But Confluent has developed, tested, and supported JDBC Sink Connector and eventually open-sourced under Confluent Community License so we have integrated JDBC Sink Connector with Apache Kafka.
There won’t be any exception thrown from the topic even if we send the incorrect schema or no schema at all because the Kafka topic accepts all messages or records as byte arrays in key-value pairs. Before transmitting the entire message to the topic, the producer has to convert the message into a byte array by using serializers.
Below is the sample schema that is bonded with payload or actual data that has to be published from the Apache Kafka message producers.
And Java code snippet for message producer
package com.dv.kafka.producer;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.connect.json.JsonSerializer;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.og.kafka.util.IKafkaConstants;
public class ProducerWithSchema {
private String status = "Failed";
private String paylaodWithSchema = "{ \"schema\": { \"type\": \"struct\", \"fields\": [{ \"type\": \"int32\", \"optional\": false, \"field\": \"deviceId\" }, { \"type\": \"string\", \"optional\": false, \"field\": \"deviceData\" }, { \"type\": \"int64\", \"optional\": false, \"name\": \"org.apache.kafka.connect.data.Timestamp\", \"version\": 1, \"field\": \"generatedTime\" } ] }, \"payload\": { \"deviceId\": 3000, \"deviceData\": \"PPPPPwfgjijk\", \"generatedTime\": 1401984166000} }";
private String key = "first";
public Producer createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, IKafkaConstants.KAFKA_BROKERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, IKafkaConstants.CLIENT_ID);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class.getName());
//props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class.getName());
System.setProperty("org.apache.logging.log4j.level", "INFO");
return new KafkaProducer(props);
}
public String sendMsgToTopic(){
Producer producer = null;
ObjectMapper objectMapper = new ObjectMapper();
try {
JsonNode jsonNode = objectMapper.readTree(paylaodWithSchema);
ProducerRecord<String, JsonNode> record = new ProducerRecord<String, JsonNode>(IKafkaConstants.TOPIC_NAME,jsonNode);
producer = this.createProducer();
producer.send(record);
producer.flush();
producer.close();
}catch (Exception e) {
System.out.println("Error in sending record");
System.out.println(e.getMessage());
}
return status;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
new ProducerWithSchema().sendMsgToTopic();
}
}
Of course, with the above approach, a couple of bottlenecks are there like
– Tightly coupled between messages and schema
– Every time schema should be clubbed with actual data
– Issues with schema evolution
– Code maintainability etc.
To mitigate or resolve the above issues, the Schema Registry has been introduced as a separate component where all the schemas would be deployed/maintained. Compatibility checks are necessary during schema evolution to make sure, the producer-consumer contract is upheld and Schema Registry can be utilized to achieve this.
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable.
By Gautam Goswami