17Jan
Ingesting Big Data into HDFS
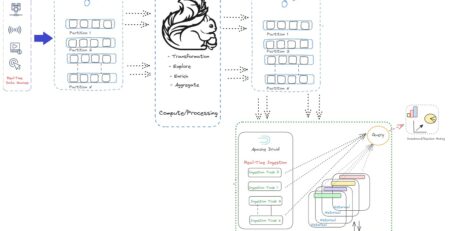
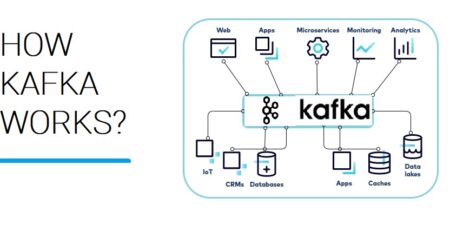
we are always talking about Big data processing using Hadoop. And know the basic definition of Big Data which is huge volume of data those can not be stored in existing traditional database or data repository. Interestingly, how can we import such a huge volume of data to the cluster of computers where Hadoop is installed? Yes, using Flume we can continuously collect the stream of data. For example Twitter data can be collected for analysis of comments. Sqoop is applied to transfer data from various existing Data warehouse systems, Databases as well as from document repositories.