Knowing and valuing Apache Kafka’s ISR (In-Sync Replicas)
To get more clarity about ISR in Apache Kafka, We should first carefully examine the replication process in the Kafka broker. In short, replication means having multiple copies of our data spread across multiple brokers. Maintaining the same copies of data in different brokers makes possible the high availability in case one or more brokers go down or are untraceable in a multi-node Kafka cluster to server the requests. Because of this reason, it is mandatory to mention how many copies of data we want to maintain in the multi-node Kafka cluster while creating a topic. It is termed as a replication factor and that’s why it can’t be more than 1 (one) while creating a topic on a single-node Kafka cluster. The number of replicas specified while creating a topic can be changed in the future based on node availability in the cluster.
On a single-node Kafka cluster, however, we can have more than one partition in the broker because each topic can have one or more partitions. The Partitions are nothing but sub-divisions of the topic into multiple parts across all the brokers on the cluster and each partition would hold the actual data(messages). Internally, each partition is a single log file upon which records are written in an append-only fashion. Based on the provided number, the topic internally split into the number of partitions at the time of creation. Thanks to partitioning, messages can be distributed in parallel among several brokers in the cluster. Kafka scales to accommodate several consumers and producers at once by employing this parallelism technique. This partitioning technique enables linear scaling for both consumers and providers. Even though more partitions in a Kafka cluster provide a higher throughput but with more partitions, there are pitfalls too. Briefly, more file handlers would be created if we increase the number of partitions as each partition maps to a directory in the file system in the broker.
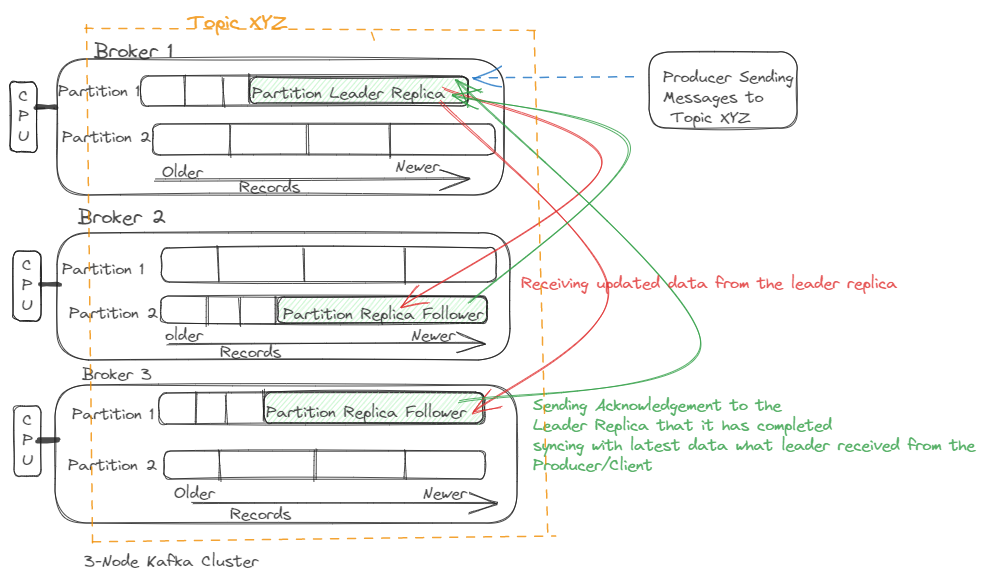
Now it would be easy for us to understand better the ISR as we have discussed replication and partitions of Apache Kafka above. The ISR is just a partition’s replicas that are “in-sync” with the leader and the leader is nothing but a replica that all requests from clients and other brokers of Kafka go to it.
Other replicas that are not the leader are termed followers. A follower that is in sync with the leader is called an ISR (in-sync replica). For example, if we set the topic’s replication factor to 3, Kafka will store the topic-partition log in three different places and will only consider a record to be committed once all three of these replicas have verified that they have written the record to the disc successfully and eventually send back the acknowledgment to the leader.
In a multi-broker (multi-node) Kafka cluster (please click here to read how a multi-node Kafka cluster can be created), one broker is selected as the leader to serve the other brokers, and this leader broker would be responsible to handle all the read and write requests for a partition while the followers (other brokers) passively replicate the leader to achieve the data consistency.
Each partition can only have one leader at a time and handles all reads and writes of records for that partition. The Followers replicate leaders and take over if the leader dies. By leveraging Apache Zookeeper, Kafka internally selects the replica of one broker’s partition and if the leader of that partition fails (due to an outage of that broker), Kafka chooses a new ISR (in-sync replica) as the new leader.
When all of the ISRs for a partition write to their log, the record is said to have been “committed” and the consumer can only read committed records. The minimum in-sync replica count specifies the minimum number of replicas that must be present for the producer to successfully send records to a partition.
Even though the high number of minimum in-sync replicas gives a higher persistence but there might be a repulsive effect too in terms of availability. The data availability automatically gets reduced if the minimum number of in-sync replicas won’t be available before publishing. The minimum number of in-sync replicas indicates how many replicas must be available for the producer to send records to a partition successfully.
For example, if we have a 3-node operational Kafka cluster with minimum in-sync replicas configuration as 3, and subsequently if one node goes down or unreachable then the rest other two nodes will not be able to receive any data/messages from the producers because of only 2 active/available in sync replicas across the brokers. The third replica which existed on the dead or unavailable broker won’t be able to send the acknowledgment to the leader that it was synced with the latest data like how the other 2 live replicas did on the available brokers in the cluster.
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable.
By Gautam Goswami