Apache Kafka, The next Generation Distributed Messaging System

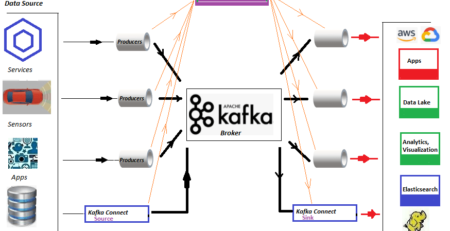
In Big Data project, the main challenge is to collect an enormous volume of data. We need distributed high throughput messaging systems to overcome it. Apache Kafka is designed to address the challenge. It was originally developed at LinkedIn Corporation and later on became a part of Apache project. A Messaging System is typically responsible for transferring data from one application to another.
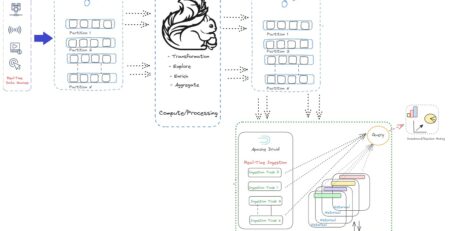
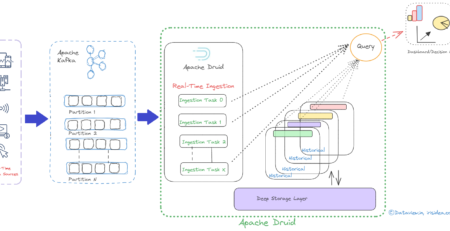
A message is nothing but the bunch of data/information. To ingest huge volume of data into Hadoop Distributed File System (HDFS), we need to have distributed messaging system that runs on a cluster of servers and Kafka is an excellent choice for it. Kafka is very easy to scale out and offer high throughput.
Kafka supports multi-subscribers and automatically balances the consumers during failure. Besides, Kafka persists messages on systems disk and thus can be used for batched consumption of messages such as ETL (Extraction, Transformation and Loading).