The Brain and Convolutional Neural Network (CNN)
 In the beginning of our life parents/family used to tell us name of the objects we see. We learned by examples given to us. Slowly we started recognizing certain things more often. They became so common that next time we saw them we would instantly know the name of the object and details of that. We label every object based on what we have learnt in the past.
In the beginning of our life parents/family used to tell us name of the objects we see. We learned by examples given to us. Slowly we started recognizing certain things more often. They became so common that next time we saw them we would instantly know the name of the object and details of that. We label every object based on what we have learnt in the past.
This is what we subconsciously do all days, we see, label, make prediction and recognize pattern. But how our brain does this. How the collaboration between eyes and brain works.
The collaboration between eyes and brain called primary visual pathway, is the reason we can can sense the world around us. When we see objects, the light receptors in our eyes sends signals via optic nerve to the primary visuals cortex, where input is being processed.
The deeply complex hierarchy structure of neurons and connections in brain plays a major role in this process of remembering and labeling objects.
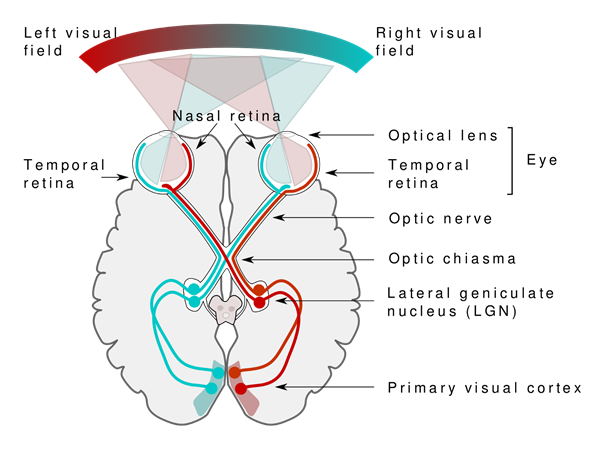
The Visual Pathway — Source: https://commons.wikimedia.org/wiki/File:Human_visual_pathway.svg
Suppose a baby experiences 1 saccade per second for 8 hours a day for 365 days. 1*60*60*8*365=10,000,000 training examples to learn to be able to see.
Convolution Neural Network(CNN)
Similar to how a child learns to recognise objects, we need to come up with an algorithm with millions of pictures before able to generalise the input and make prediction for image it has not seen before. In digital world image represented as 2-dimensional array of numbers, known as pixels. To learn how to recognise an object we use specific type of algorithm called Convolution Neural Network (CNN)
 In this paper, it describes two types of visual neurons cells in brain, each of them acts in a different way. They are called simple cells (S Cell) and Complex cells (C Cells). The Simple Cells activate when they identify the basic shapes as lines in fixed area and specific angle. The complex cells have large receptive field and their output is not sensitive to the specific position. The complex cells continue to respond to a certain stimulus, even though its absolute position on the retina changes. Complex refers to more flexible, in this case.
In this paper, it describes two types of visual neurons cells in brain, each of them acts in a different way. They are called simple cells (S Cell) and Complex cells (C Cells). The Simple Cells activate when they identify the basic shapes as lines in fixed area and specific angle. The complex cells have large receptive field and their output is not sensitive to the specific position. The complex cells continue to respond to a certain stimulus, even though its absolute position on the retina changes. Complex refers to more flexible, in this case.
In vision, a receptive field of a single sensory neuron is the specific region of the retina in which something will affect the firing of that neuron (that is, will active the neuron). Every sensory neuron cell has similar receptive fields, and their fields are overlying.
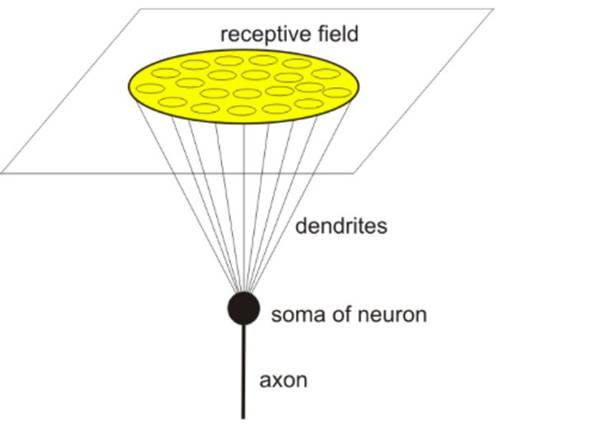
A neuron’s receptive field
Further, the concept of hierarchy plays a significant role in the brain. Information is stored in sequences of patterns, in sequential order. The neocortex, which is the outermost layer of the brain, stores information hierarchically. It is stored in cortical columns, or uniformly organised groupings of neurons in the neocortex.
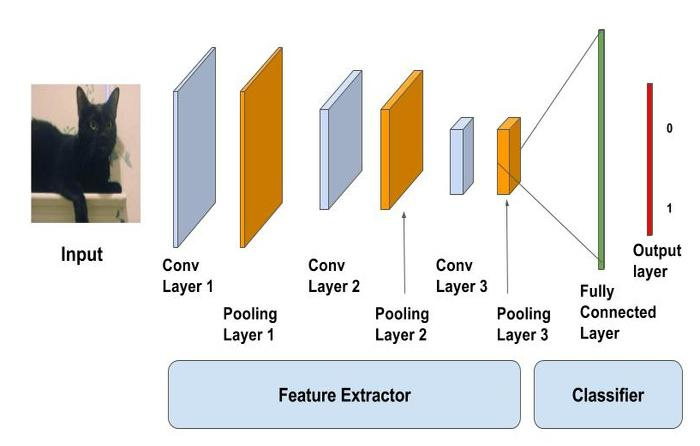
Convolution Neural Networks (CNN) have a different architecture then the regular neural network.
CNNs have two components:
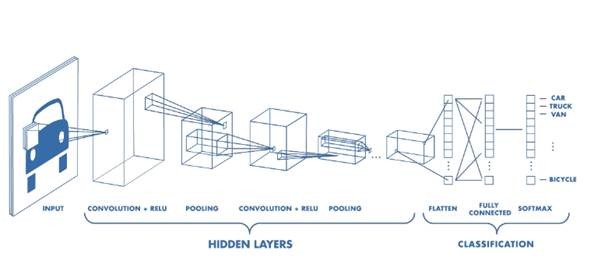 1. Hidden Layers/Feature extraction
1. Hidden Layers/Feature extraction
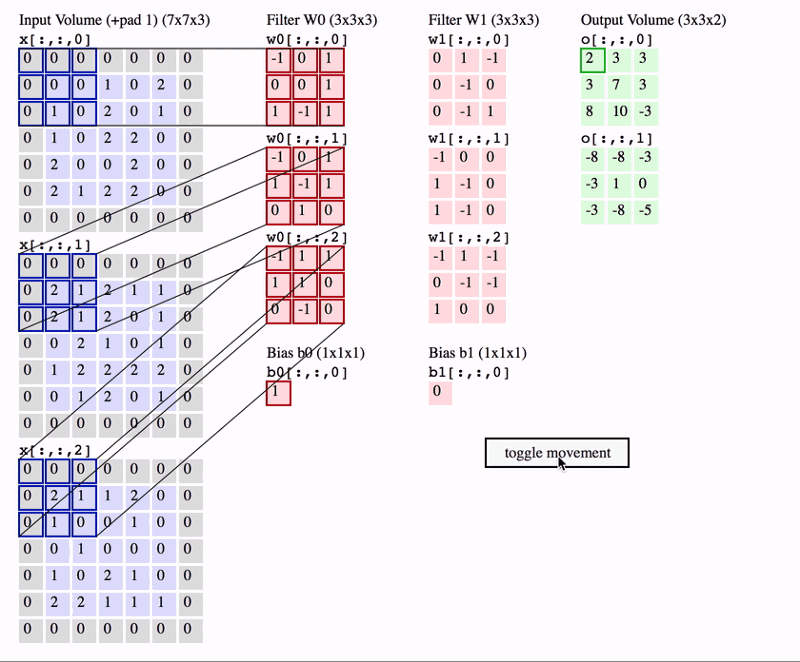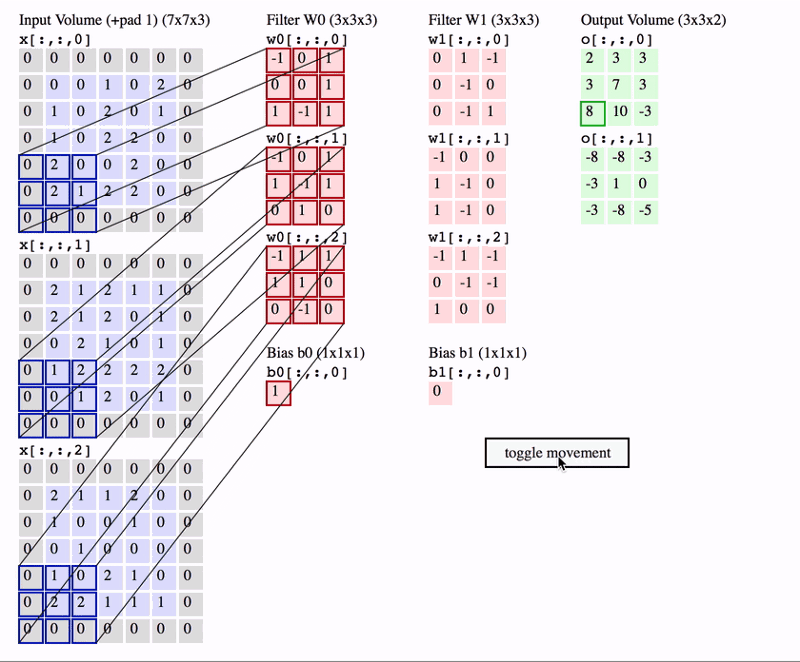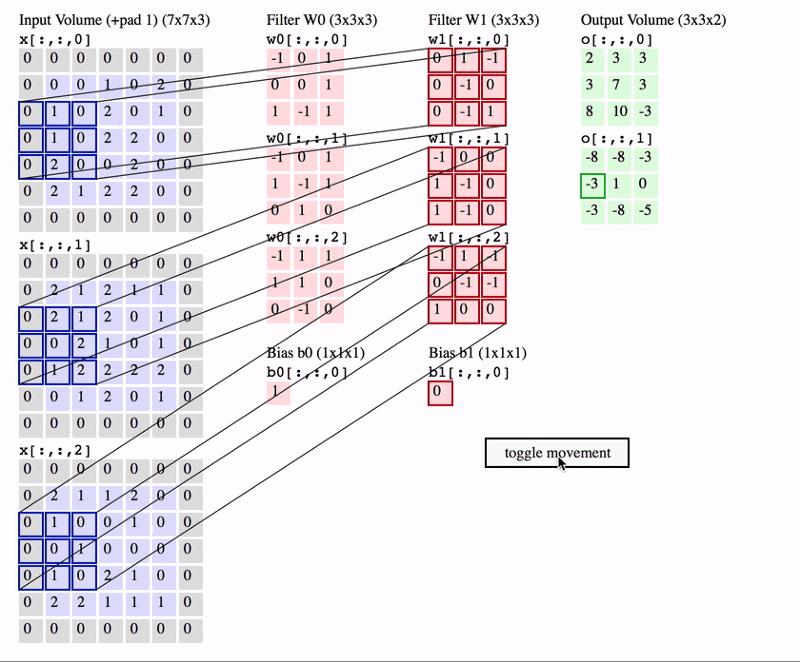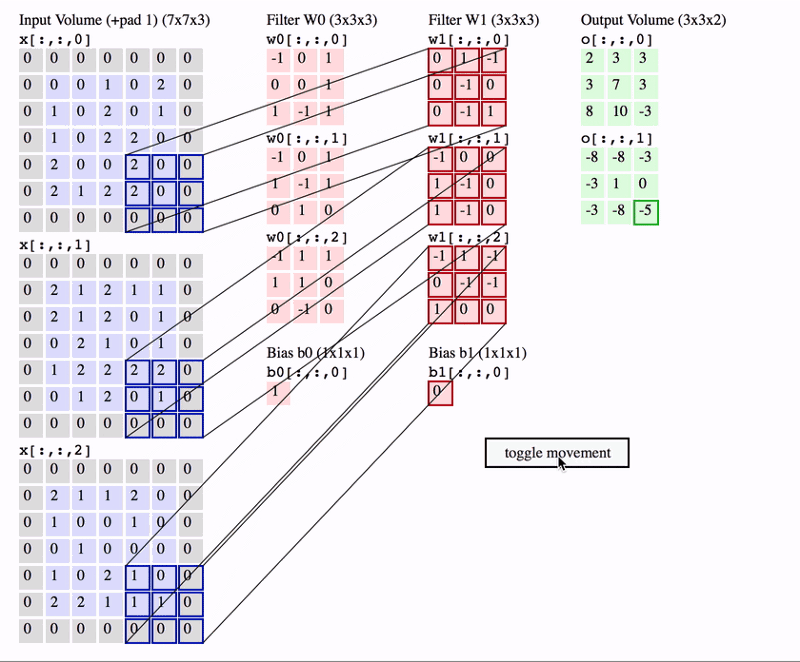
In the hidden layers, network will perform series of convolutions and pooling operations during which features are detected. Convolution is performed in the input data with the use of a filter, and this produces a feature map. We execute a convolution, at every location a matrix multiplication is performed and sums the result onto the feature map.
In the below picture you can see how the convolution is performed. Each image is namely represented as a 3d matrix with dimension for width, height and depth. Depth is a dimension because colors channels used in an image(RGB).
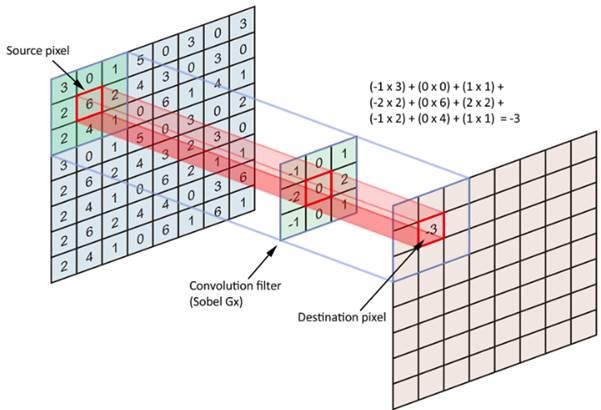 The filter slides over the input and performs its output on the new layer
The filter slides over the input and performs its output on the new layer
We perform numerous convolutions on our input where each operation uses a different filter. This results in different feature maps. In the end,we take all these feature maps and put them together as a final output of the convolution layer.
The output of convolution will be passed through the activation function. This could be ReLU (Rectified Linear Unit) activation function. Activation function is used to make the output non-linear.
A rectified linear unit has output 0 if the input is less than 0, and raw output otherwise. That is, if the input is greater than 0, the output is equal to the input. ReLUs’ machinery is more like a real neuron in your body.

When you get the input positive, the derivative is just 1, so there isn’t the squeezing effect you meet on back propagated errors from the sigmoid function. Because of the feature map is always smaller than the input, chances of shrinking the feature map is very high. To prevent this from shrinking we use padding.
A layer of zero-value pixels is added to surround the input with zeros, so that our feature map will not sh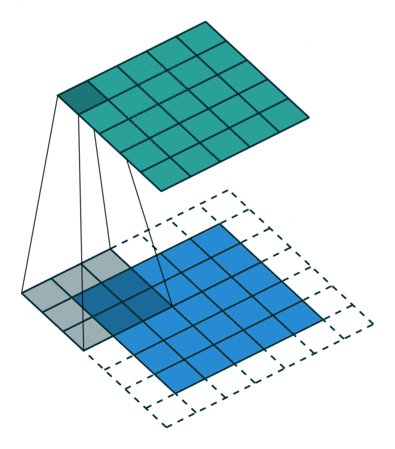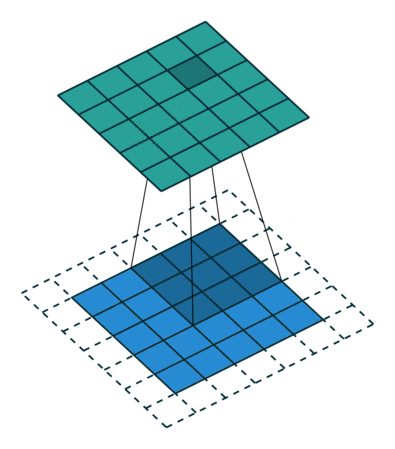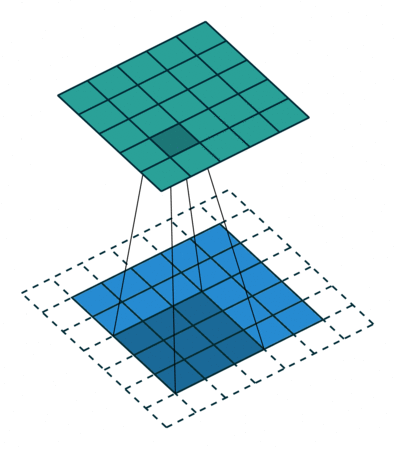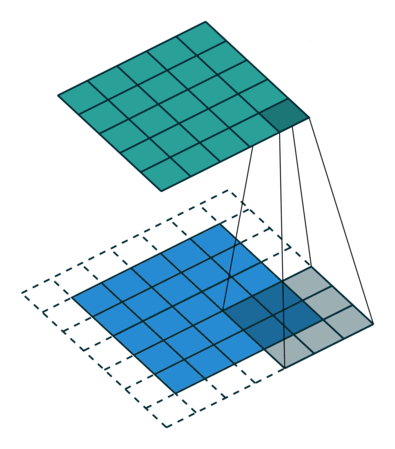 rink. In addition to keeping the spatial size constant after performing convolution, padding also improves performance and makes sure the kernel and stride size will fit in the input.
rink. In addition to keeping the spatial size constant after performing convolution, padding also improves performance and makes sure the kernel and stride size will fit in the input.
The animation below shows stride size 1 and padding with dotted line
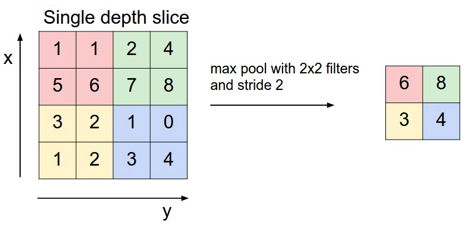
After a convolution layer, it is common to add a pooling layer in between CNN layers. The function of pooling is to continuously reduce the dimensionality to reduce the number of parameters and computation in the network. This shortens the training time and controls overfitting.
The most frequent type of pooling is max pooling, which takes the maximum value in each window. These window sizes need to be specified beforehand. This decreases the feature map size while at the same time keeping the significant information.
A nice way of visualising CNN is shown below
 2. Classification layer
2. Classification layer
In classification Layer, the fully connected layer will serve as a classifiers on top of these extracted features. It will assign probability for the object on the image being what the algorithm predicts it is.
After Convolution and pooling layer classification part consists of fully connected layers. These fully connected layers accept data in One dimensional data only. To convert 3D data to 1D we use function flatten in python.
The last layers of a Convolution NN are fully connected layers. Neurons in a fully connected layer have full connections to all the activations in the previous layer. This part is in principle the same as a regular Neural Network.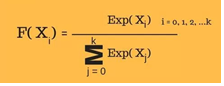
And then we are applying the softmax function for classification problem, The softmax function squashes the outputs of each unit to be between 0 and 1, just like a sigmoid function.
But it also divides each output such that the total sum of the outputs is equal to 1.
Here is the formula for calculating softmax
Here is how the output of the model looks like after training the data using CNN
model.summary
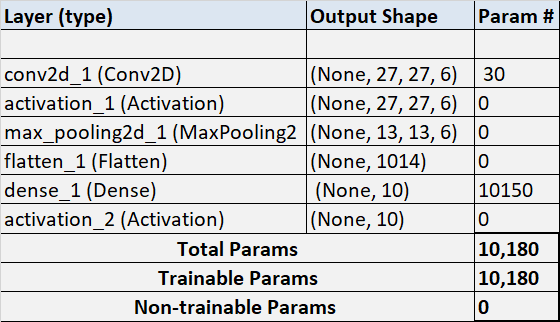 ______________________________________________________________
______________________________________________________________
Summary
In Summary CNN is very useful in image classification and recognition, where filter slides over input and merge input + the filter value on the feature map.
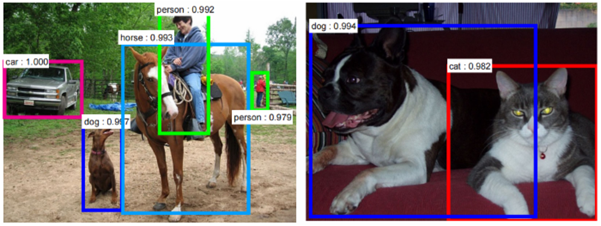
In the end, our goal is to feed new images to our CNN so it can give a probability for the object it thinks it sees or describe an image with text.
 This Article is written by: Vijay Kumar PMP® , CSM®
This Article is written by: Vijay Kumar PMP® , CSM®