13Oct
Understanding Apache Druid Supervisor and its specification for real-time data ingestion from Apache Kafka
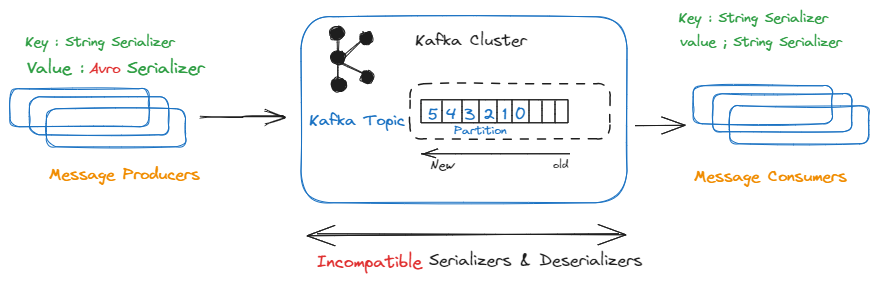
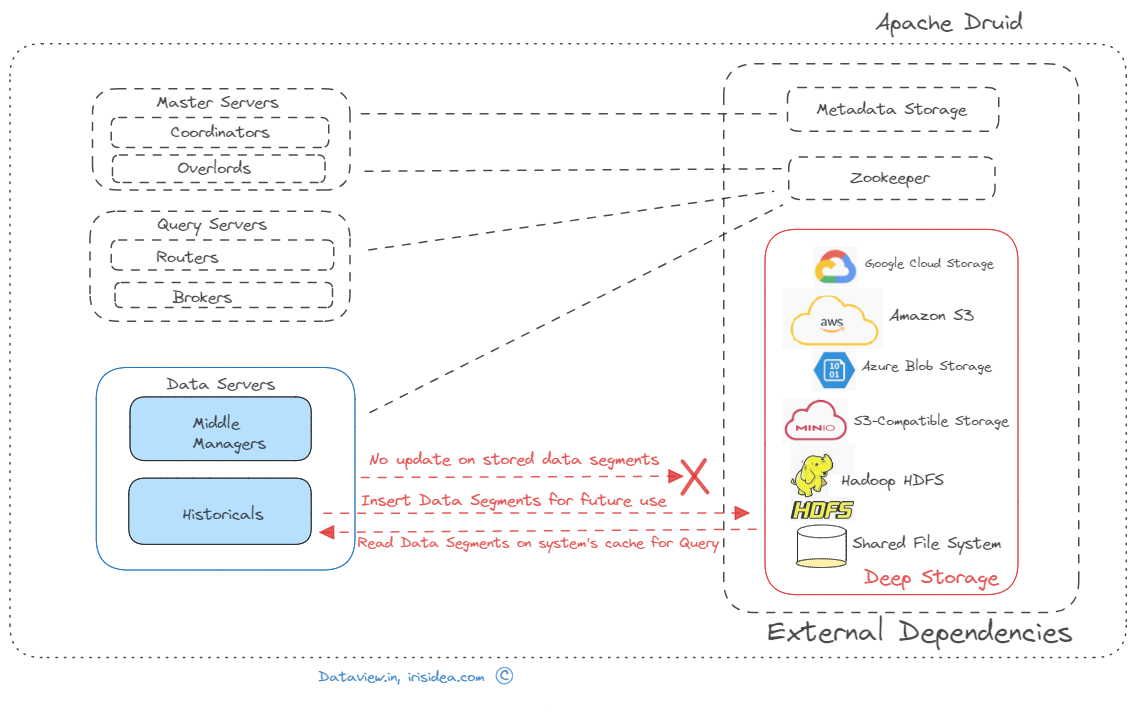
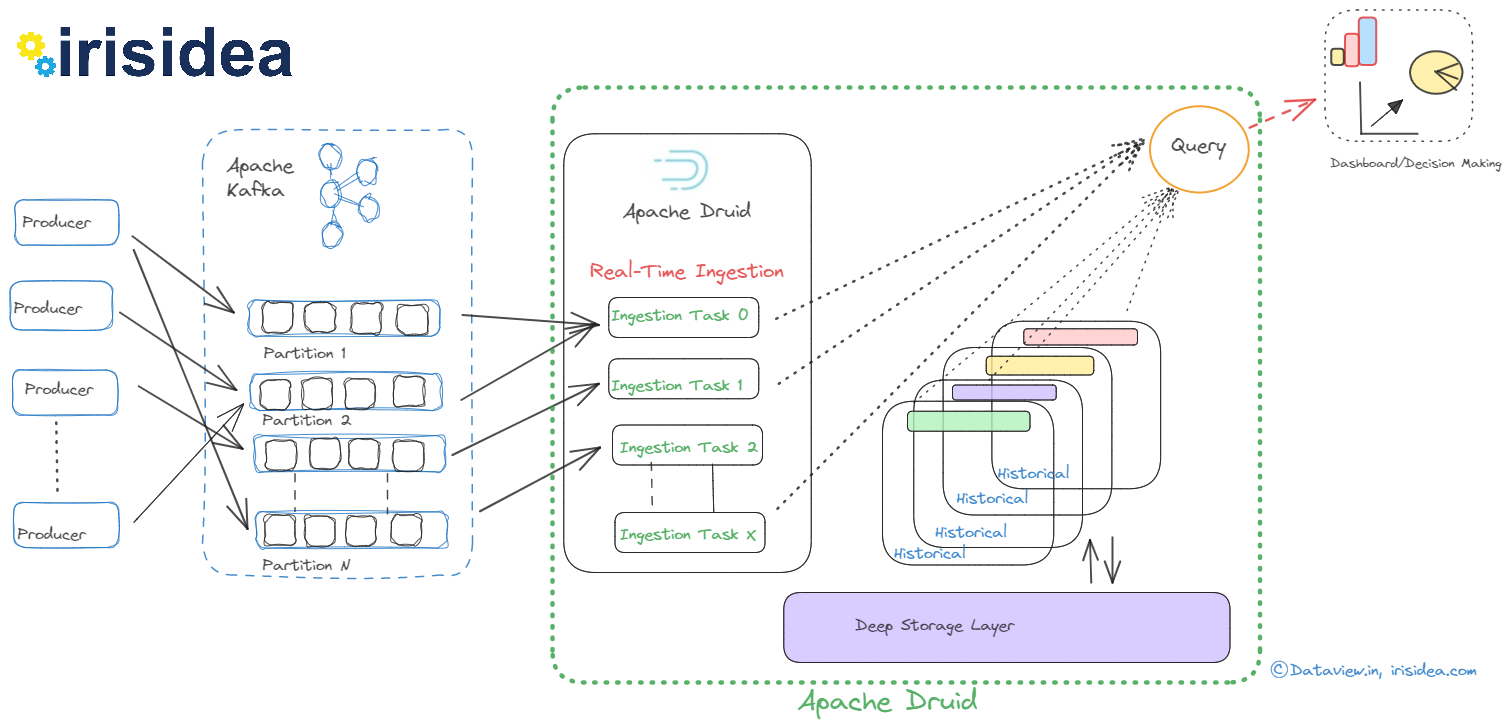
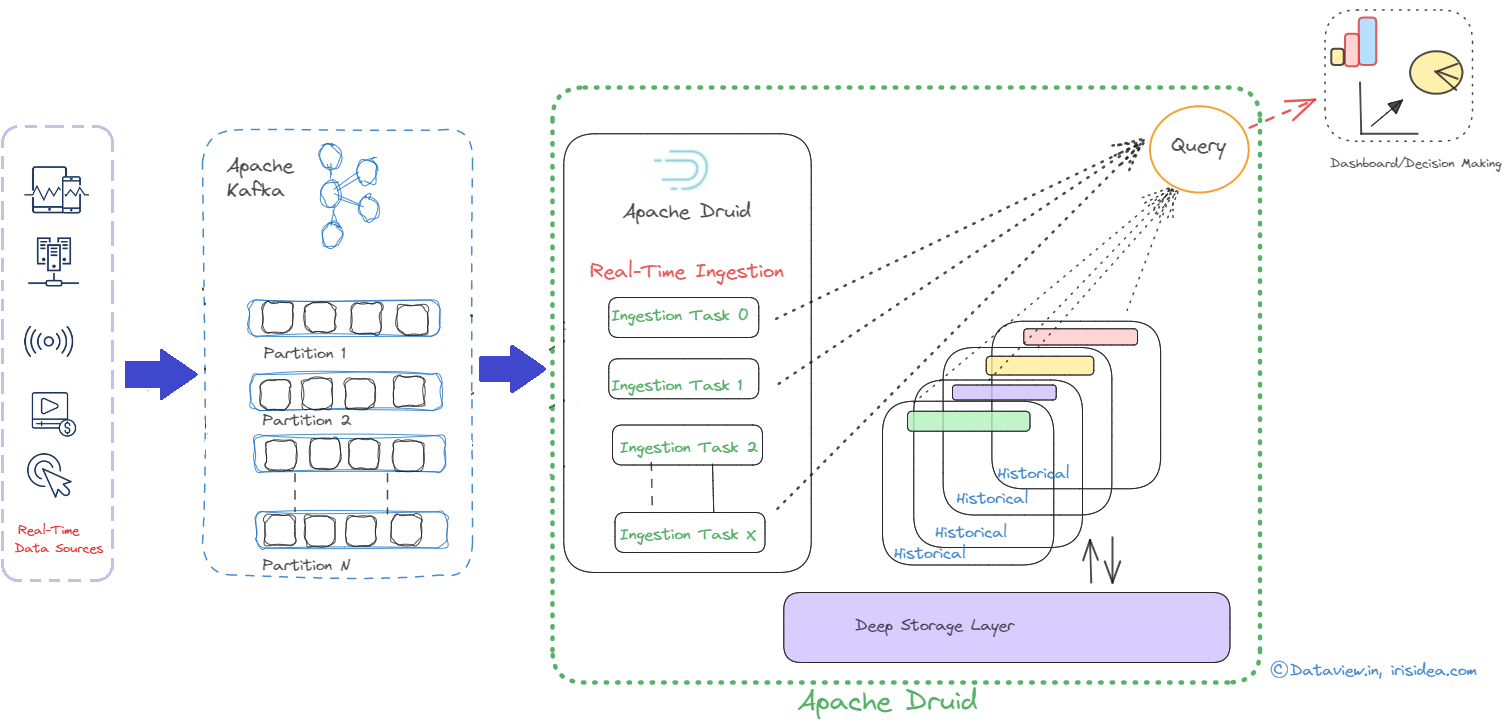
Although both Apache Druid and Apache Kafka are potent open-source data processing tools, they have diverse uses. While Druid is a high-performance, column-store, real-time analytical database, Kafka is a distributed platform for event streaming. However, they can work together in a typical data pipeline scenario where Kafka is used as a messaging system to ingest and store data/events, and Druid is used to perform real-time analytics on that data. In short, the indexing is the process of loading data in Druid...