06Jan
Few intrinsic of Apache Zookeeper and their importance
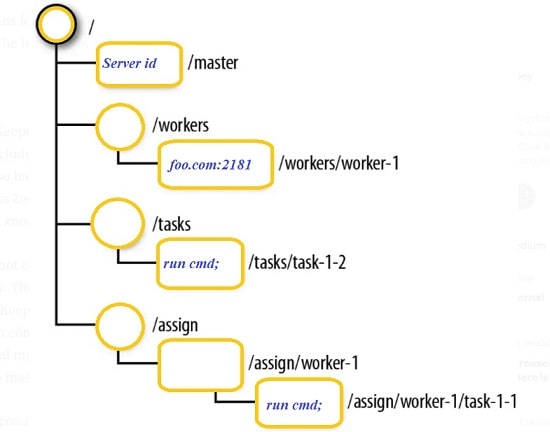
As a bird’s eye view, Apache Zookeeper has been leveraged to get coordination services for managing distributed applications. Holds responsibility for providing configuration information, naming, synchronization, and group services over large clusters in distributed systems. To consider as an example, Apache Kafka uses Zookeeper for choosing their leader node for the topic partitions. Please click here if you want read on how to setup the multi-node Apache Zookeeper cluster on Ubuntu/Linux zNodes The key concept of the Zookeeper is the znode which can be acted...