16Nov
Overcome LEADER_NOT_AVAILABLE error on Multi-node Apache Kafka Cluster
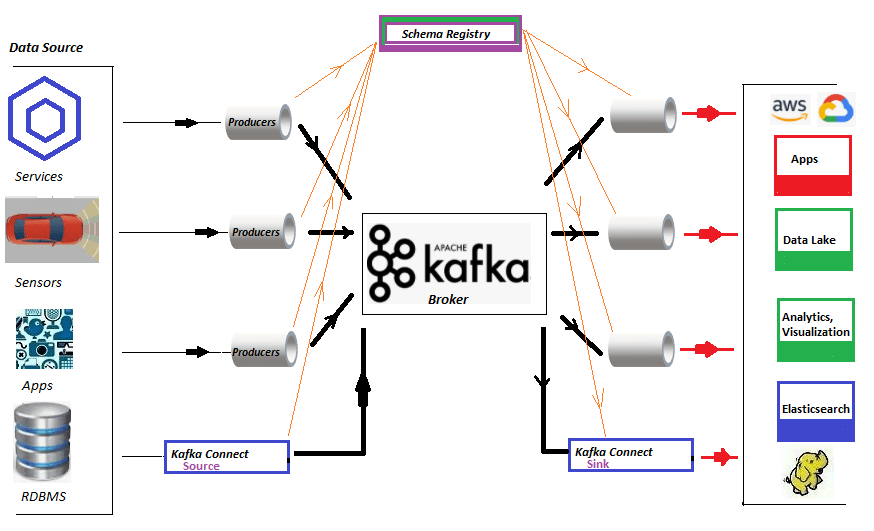
Kafka Connect assumes a significant part in streaming data between Apache Kafka and other data systems. As a tool, it holds the responsibility of a scalable and reliable way to move the data in and out of Apache Kafka. Importing data from the Database set to Apache Kafka is surely perhaps the most well-known use instance of JDBC Connector (Source & Sink) that belongs to Kafka Connect. This short article aims to elaborate on the steps on how can we...