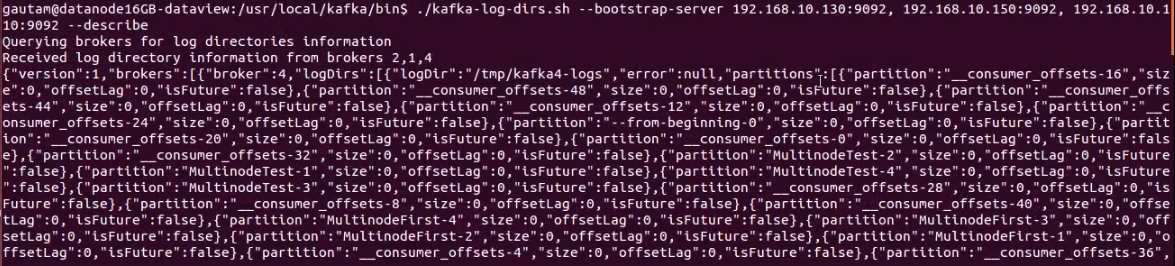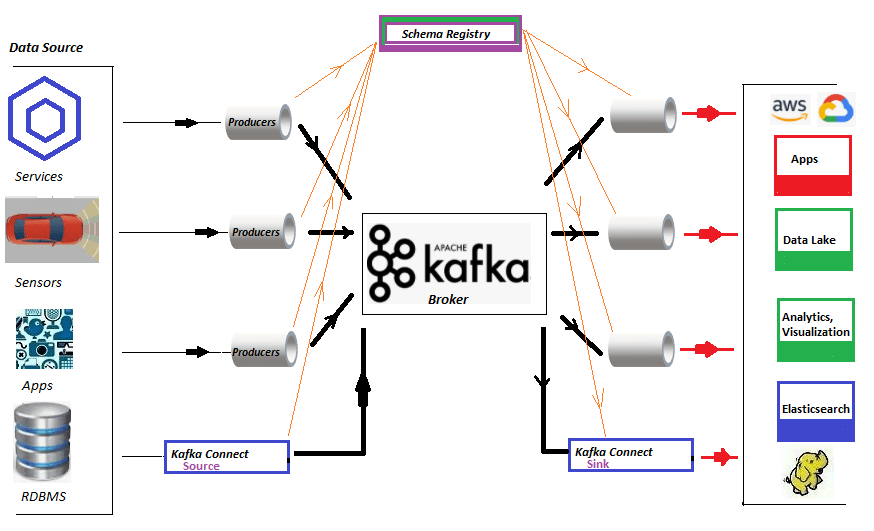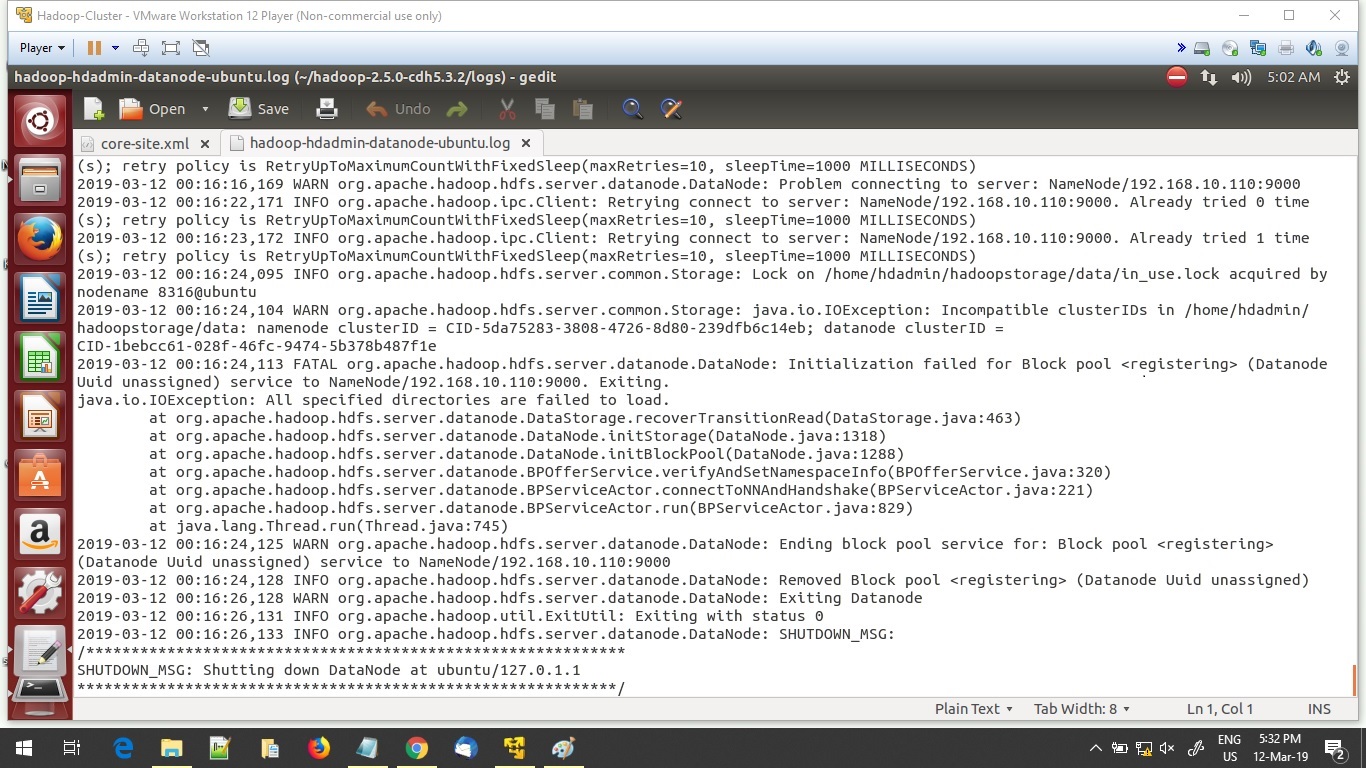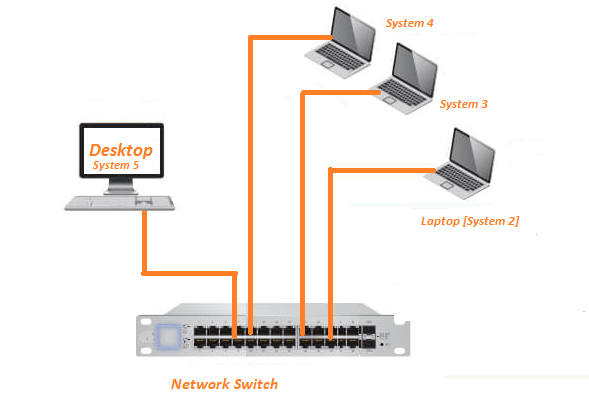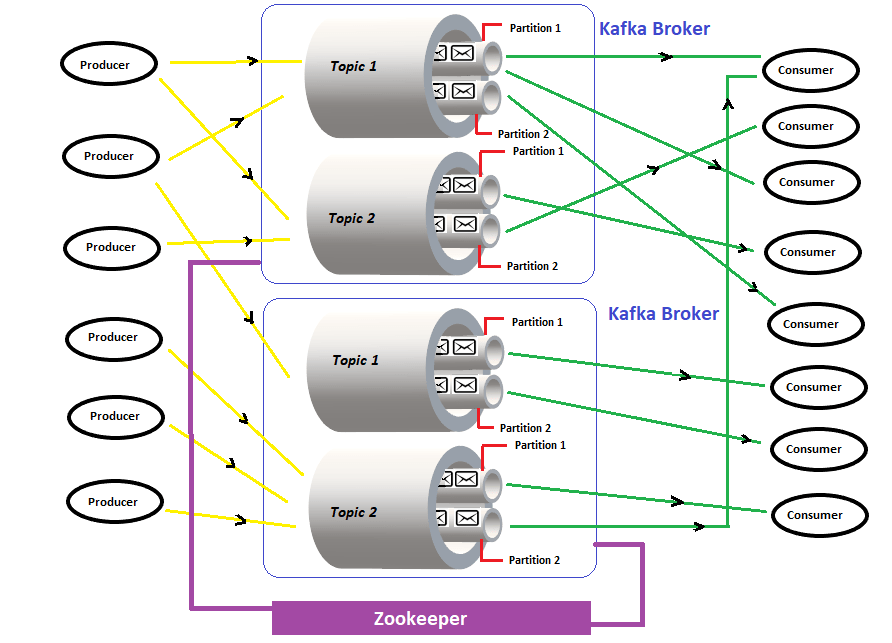
02Oct
Crafting a Multi-Node Multi-Broker Kafka Cluster- A Weekend Project
For the past couple of years, there has been a huge development in the appropriation of Apache Kafka. Kafka is a scalable pub/sub system and in a nutshell, is designed as a distributed multi-subscription system where data persists to disks. On top of it as a highlight, Kafka delivers messages to both real-time and batch consumers at the same time without performance degradation. Current users of Kafka incorporate Uber, Twitter, Netflix, LinkedIn, Yahoo, Cisco, Goldman Sachs, and so forth....